Level DBとLSM-TreeにおけるCompaction問題
LevelDB が持つ Log structured marge tree(通称 LSM-Tree)の概要と、追記を行うにあたって発生するコンパクションの概要とその問題について調べたのでログに残す。
LevelDB
Google が 2011 年に公表した OSS ライブラリの LevelDB は、BigTable の内部実装を参考に構築された。 この使い勝手が良く高性能な KVS は Chrome,BitCoin,AutoCAD 等にも利用されていた。
DB という名前がついているが SQL 等は動かず、実際の利用方法としては大きなマップ(言語によってハッシュ・連想配列等々の呼び名)に近い。
任意のバイト列のキーに対して、値のセット・取得が行える。
キーによってソートされており(例: AZ)特定のキー範囲(例: CE)を取得することも行える。
また Facebook による Fork プロジェクト RocksDB によって、マルチコア・SSD 等を活かすパフォーマンス改善や多数の機能追加が行われており、 ArangoDB,Ceph,TiKV 等の高性能な KVS が必要とされる場所に採用されている。
基本的なアーキテクチャは LevelDB と変わらないが、機能・性能・メンテナンス状況等から RocksDB を採用することが多い。 性能チューニングなどの論文も RocksDB のプラグインとして実装されたものが多数出ているので、主に RocksDB の設定等を中心に紹介する。
LSM Tree
LSM Tree はレベル毎にサイズの異なるログによるツリー構造で構成される。 ログレコードには Key,Value(TTL 等も)を含めることが出来、Insert と Index Lookup,Scan 等を現実的なコストで行える性能特性を持つ。 この LSM Tree には以下の規則が存在する。
- 共通
- レベルごとに複数(数個~十数個まで)のログが含まれる
- レベルの数字が高くなるほどにログの最大容量は大きくなる
- 各レベルでキーが重複するケースは許容され、その場合は Level 数が小さいログに格納された値を取る
- Level 0
- ログに順不同・範囲の制約を行わずにデータが格納
- Level 1 以降
- ログ内の値は全てキーによってソートされている
- ログのキー範囲はそれぞれ重複しない
- 言い換えると各レベルにあるキーが存在しうるログは 1 つだけ
 https://en.wikipedia.org/wiki/File:LSM_Tree.png
https://en.wikipedia.org/wiki/File:LSM_Tree.png
{kind=link}
このことから、以下のような性能特性を持つ。
- Insert
- Level 0 に対してのログ追記のみで完了する
- Index Lookup
- 全ての Level 0 ログの検索・該当するキーが含まれるソートされた Level 1,… Level N の N 個のログから値を探す
- 最良ケースは対象が Level 0 の直近に書き込まれたレコードレコード
- 最悪ケースは最後の Level に格納されたレコードの場合
- Scan
- 全ての Level 0 ログ・キー対象が含まれる全 Level のログを検索する
- Level 1 以降はソートされており局所性が高い
- 各レベルのレコードはマージソートの要領で収集
- Delete
- レコードの削除は通常高コスト
- IO を減らすために「削除したマーク」を Level 0 に対して追記する事が一般的
- 不要なデータは後述のコンパクション等で削除する事が多い
各レベルは以下のように重複しない担当キー範囲を持っているので高速なキー検索を行うことが出来る。
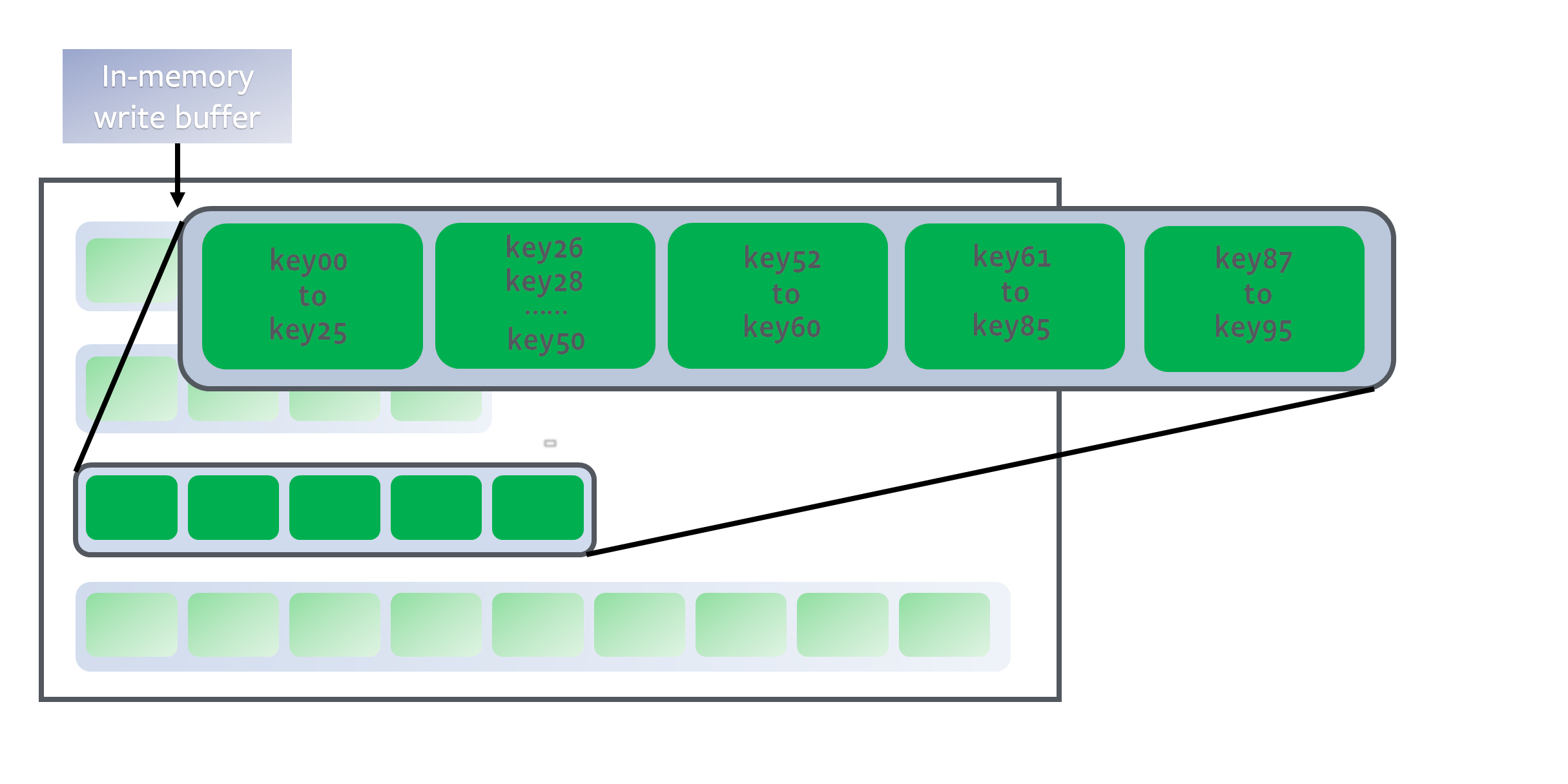 https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
RocksDB の場合、Level1 に格納されるログの容量は max_bytes_for_level_base (デフォルト値 10MB)で、Level 毎に max_bytes_for_level_multiplier (デフォルト値 10)掛けられた大きさとなり、レベルの最大値は num_levels (デフォルト値 6)となる。
なお、レベルごとのログの大きさは level_compaction_dynamic_level_bytes 等の他のオプションによって、適切なサイズに変更されることも有る。
| Level | 容量 |
|---|---|
| Level 1 | 10MB |
| Level 2 | 100MB |
| Level 3 | 1GB |
| Level 4 | 10GB |
| Level 5 | 100GB |
| Level 6 | 1TB |
memtable
LevelDB,RocksDB は共にディスクに永続化される L0 の手前にメモリ内のデータ構造として memtable を持つ。
ログを memtable に書き込み、一定の容量になるとそのバッファは読み取り専用としてマークされ、新たな書き込みバッファが作成される。 そしてバッファの数が一定数を超えると、読み取り専用バッファ間での値の重複を取り除き、L0 が作成される。
RocksDB の場合バッファ容量は write_buffer_size で設定可能で、数 MB ~数十 MB を指定することが多い。L0 の書き書き込みはバッファの数が min_write_buffer_number_to_merge (デフォルト値 1)を超えると行われる。
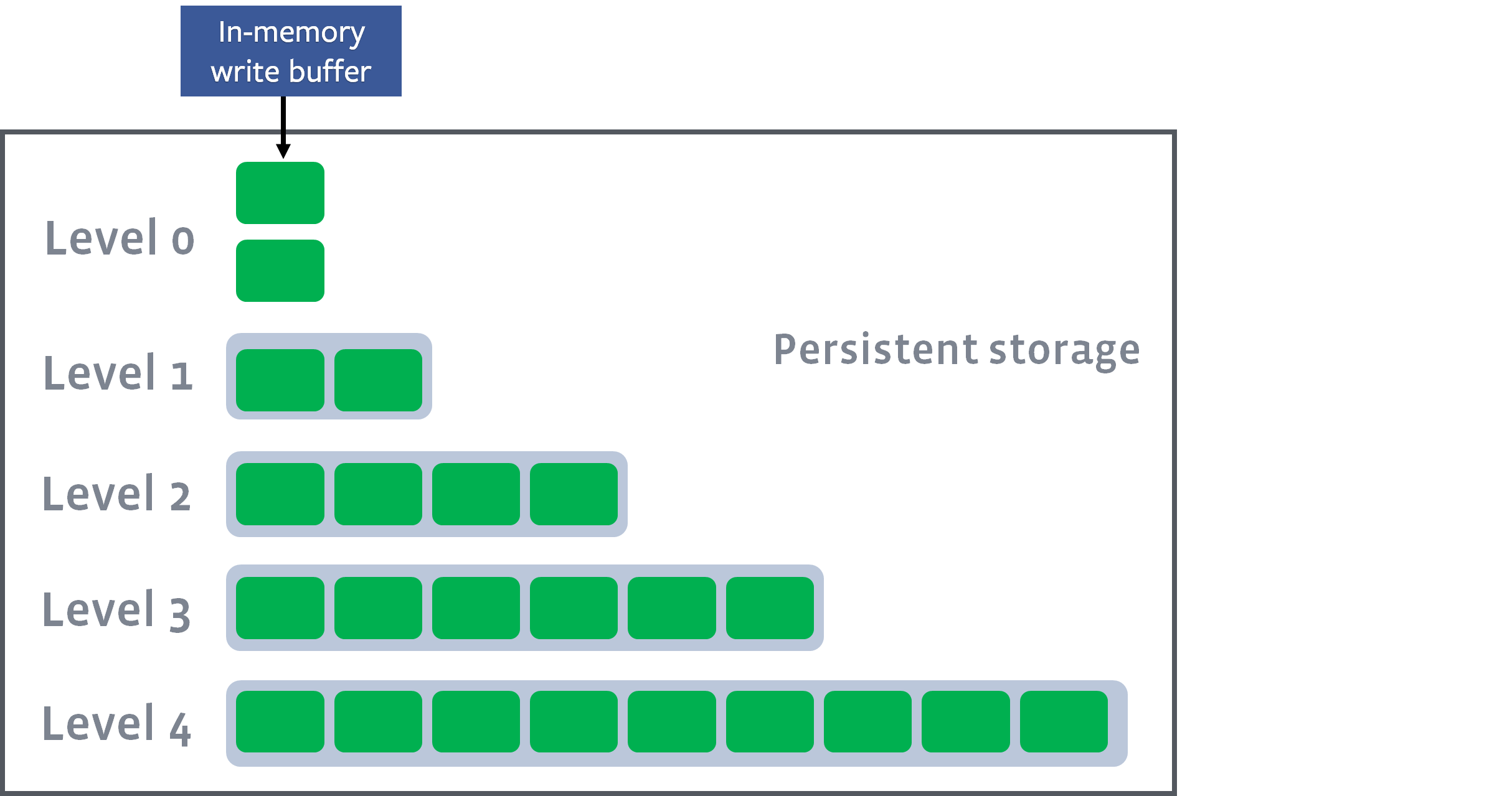
LSM Tree のコンパクション
先の章で分かるように、Level 0 のログはアクセスの度にフルスキャンが行われることになり、追記によってログの数やレコード件数が増えると検索に時間が掛かる。 また Level 1 以降のファイル数が増えれば、ファイルを開くまでのレイテンシの増加やファイルディスクリプタ等の OS 資源をより多く使うため好ましくない。
そのため、レコード件数・レベルの容量が一定の閾値を超えたタイミングでマージを行い、上位のレベルファイルを生成する。 この処理をコンパクションと呼んでいる。 (同じようなタイミングで compression,compaction を利用して紛らわしい)
例えば RocksDB の場合、L0 のファイル数が level0_file_num_compaction_trigger (デフォルト値 4) を上回ると、Level 1 とのマージが始まる。
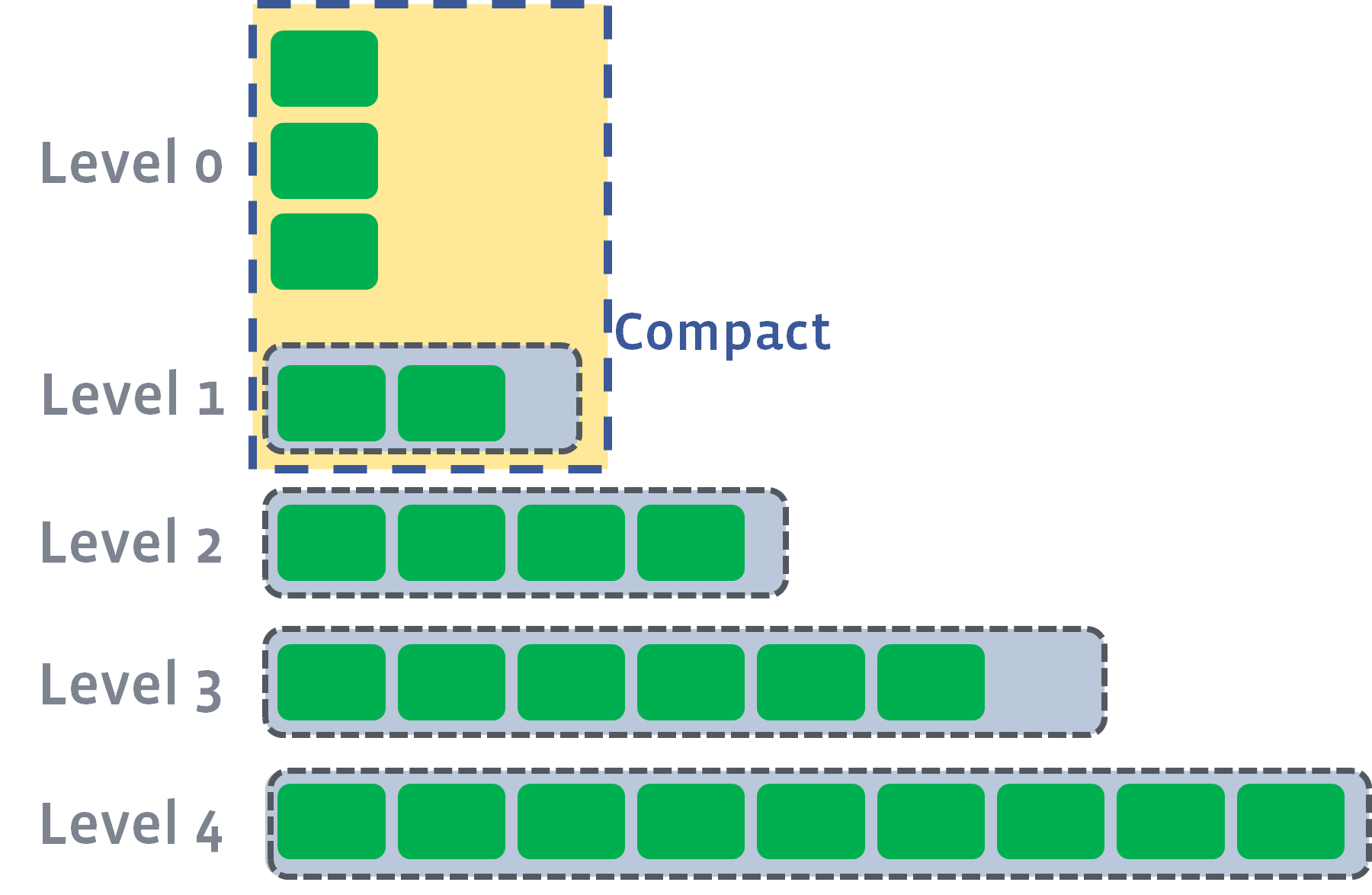
その際に Level 1 が max_bytes_for_level_base (デフォルト値 10MB)を超えていれば Level 2 とのコンパクションが始まる。
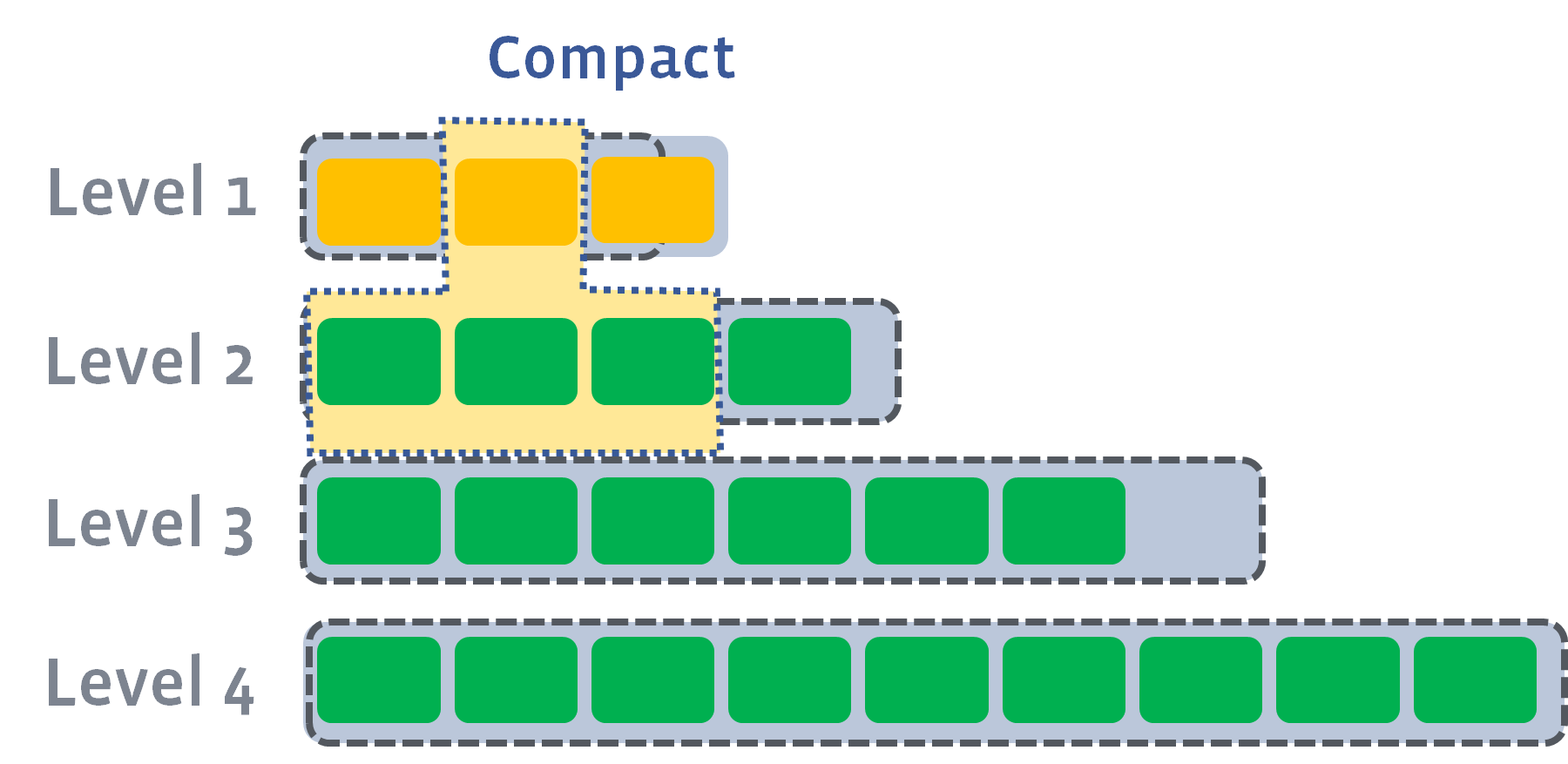
この際、キー範囲が重複していない Level 1 以降については容易に並列化が行なえ、RocksDB の場合は max_background_compactions (デフォルト値 1)で設定が可能。
画像の引用元: https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
ツリー構造の性能評価
他のデータ構造(B Tree 等)と比較する際に主に以下の 3 点を中心に比較する事が多い。
- 書き込み増幅 (Write amplification / WA)
- DB に書き込まれたデータ量と実際にストレージに書き込まれたデータ量の比
- 10MB 書き込んで 50MB 書き込まれた場合の WA は 5
- RocksDB においては 5~10 程度になる
- 読み取り増幅 (Read amplification)
- クエリに応答するために読み取ったページ数
- 回答を行うために 10 のファイル(ページ)を参照した場合の増幅は 10
- LSM Tree においては~10 程度
- アクセス頻度が高いファイル(L0,L1 等)はキャッシュに乗っており、ページ数とアクセス時間は常に比例するわけでは無い
- 空間増幅 (Space amplification)
- データベースに保持されたデータ量とストレージに保持されているデータ量の比
- データベースに 10MB 書き込んでストレージを 100MB 使う場合は 10
一般的には全ての指標が優れている可能性は低い。 例えば B Tree と LSM Tree を比較すると、B Tree は読み取り増幅が少なく、LSM Tree は書き込み増幅が少ない。
B Tree との比較 https://tikv.github.io/deep-dive-tikv/key-value-engine/B-Tree-vs-Log-Structured-Merge-Tree.html
書き込みのストール
これまで述べた LSM Tree の構造上、書き込み速度・読み取り速度のトレードオフが関係の調整は利用者が行えるようになっている。 極端な例だと以下のような事が言える。
- L0 へのログ書き込みだけを延々と行っていれば最速の書き込み速度を維持できるが、読み取り時においてはフルスキャンが常に必要となるため速度は低下する
- L2 以降へのコンパクションを行わなければ書き込み増幅が減るが、読み取り時にアクセスが必要なファイル数は大幅に増える
このような特性は通常のアプリケーションでは許容されない。 LevelDB,RocksDB は読み書きのパフォーマンスを一定に保つために、ある一定の条件の際に新規書き込みを停止させる。
- memtable が多すぎる
- Level 0 へのフラッシュを待っている memtable が多すぎると書き込みを停止する
- RockDB の場合 memtable の数が
max_write_buffer_number(デフォルト値 2) に達すると書き込みを停止する
- Level 0 のファイルが多すぎる
- ファイル数が一定以上を上回ると書き込みは抑制され、さらに増えた際には完全に書き込みが停止する
- コンパクションが Level 0 のファイル数を減らせば再び書き込みが行える
- RocksDB の場合、書き込みの抑制・停止の閾値を
level0_slowdown_writes_triggerlevel0_stop_writes_triggerで設定
- 保留中のコンパクションが多すぎる
- 推定されるコンパクションの保留バイト数が一定以上を超えると抑制され、更に増えると書き込みが停止する
- RocksDB の場合、書き込みの抑制・停止の閾値を
soft_pending_compaction_bytes(デフォルト値 64GB)hard_pending_compaction_bytes(デフォルト値 256GB) で設定
書き込みのスローダウンの程度は、 delayed_write_rate (デフォルト値 16MB/s)などで設定が可能。
書き込みスループットが、数分に 1 度谷のように落ちている箇所が有れば、ストールを表している。
https://github.com/facebook/rocksdb/wiki/Write-Stalls
書き込み増幅・書き込みストールへの対処法
多くの DB のワークロードは、99%が読み取り・1%が書き込みのようなワークロードが多い。 この場合は可能な限り読み取りを高速に行うための LSM Tree を維持する必要が有る。
しかし、読み書きのパフォーマンスは先に述べたようにトレードオフ関係となっている。 読み取りパフォーマンスを維持するために、LevelDB,RocksDB は通常 5 倍から 10 倍の書き込み増幅を引き起こし、書き込みストールも発生しうる。 これは書き込みが多いワークロードに向かない。
そこで、コンパクションの方法等をチューニングすることで書き込みスループットを高速に保つための方法がいくつか提案されている。 RocksDB 関連の資料を調べたので紹介する。
対処法 1. Sharding
まず単純な方法が、複数の KVS に分散して書き込む方法。 方法によっては読み取り増幅は増え、パフォーマンスは低下することが多い。 TiKV 等の分散 KVS を利用しているのであれば、単にノードを増やすだけでクラスタの書き込みスループットは上がる。
対処法 2. RocksDB Universal Compaction
Leveled コンパクションは小さいブロックをキー毎に分割された大きいブロックにマージするのに対し、Universal Compaction はサイズの似ているブロックをマージして大きなブロックを作成する。 全てのブロックには全ての範囲のキーレンジが含まれる可能性が有る。 これは LSM Tree ではない。
LevelDB コンパクションに比べ Universal Compaction は以下のような特徴を持つ。
- 長所
- コンパクションの負荷が低く書き込みワークロードが多い場合に適する
- 短所
- 読み取り速度は予測しづらい
- コンパクション時に一時的に保存容量の倍の容量を利用する(ディスクの実効容量は半分となる)
- サイズの大きいブロックはコンパクション対象になりにくいので、レコードの削除が実際に行われる頻度が低い
Universal Compaction は Cassandra で利用されている SizeTieredCompactionStrategy(STCS)と似た挙動となっている。
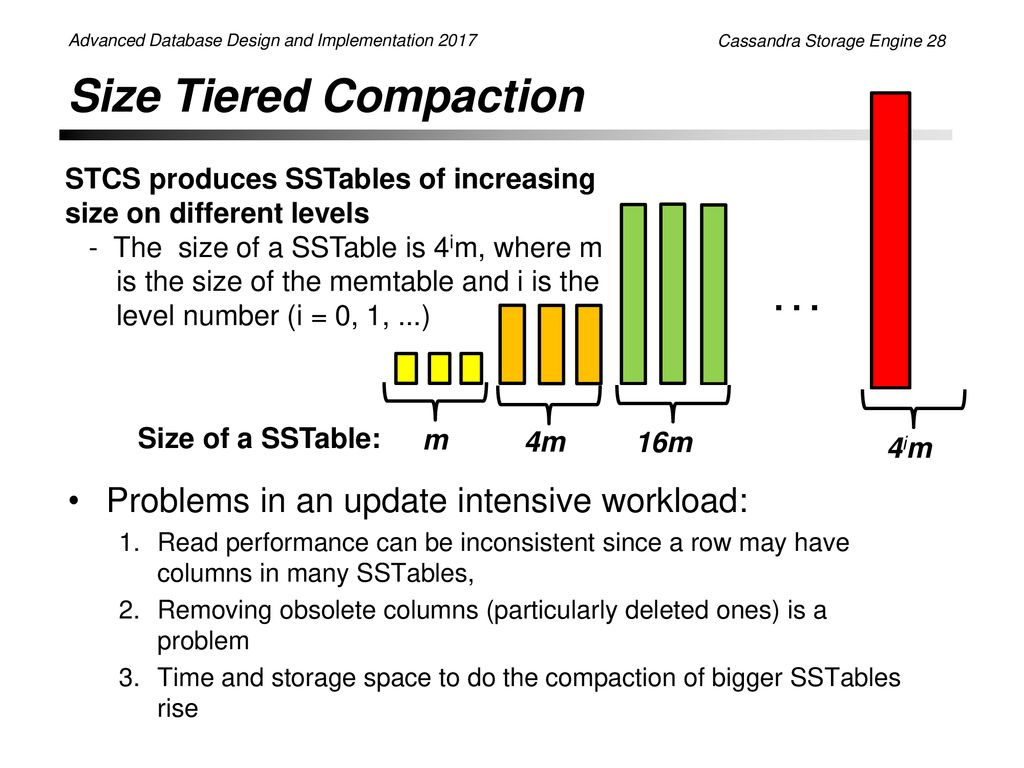
- RocksDB Universal Compaction https://github.com/facebook/rocksdb/wiki/Universal-Compaction
- Datastax DSE 5.1 データはどのように維持されるか https://docs.datastax.com/ja/dse/5.1/dse-arch/datastax_enterprise/dbInternals/dbIntHowDataMaintain.html
- Cassandra Storage Engine: https://slideplayer.com/slide/13036914/
- Scylla’s Compaction Strategies Series: Write Amplification in Leveled Compaction https://www.scylladb.com/2018/01/31/
対処法 3. NoveLSM
不揮発で高速な NVMe デバイスに memtable を置くことで高速化が行えると述べる論文。
memtable を直接変更可能とすることで memtable の数を削減でき、memtable のサイズを大きくしても読み取りパフォーマンスを良好に保てる。 memtable のサイズが大きくなることで直近のキー変更がマージされ、L0 へ出力されるサイズを減らせる可能性が高くなる。
しかしながら大きな memtable を Level 0 に書き出すので(RocksDB デフォルト値の 5 倍程度の大きさ)、Level 0,Level 1 間のコンパクションが非常に高頻度で発生し、書き込みストールが発生する可能性も高くなる事が指摘されている。
- https://www.usenix.org/sites/default/files/conference/protected-files/atc18_slides_kannan.pdf
- https://www.usenix.org/system/files/conference/atc18/atc18-kannan.pdf
対処法 4. TRIAD
書き込みが多いキーの IO 遅延・ログの重複書き込み等を減らす等の組み合わせによって、スループットを倍・書き込み増幅を 1/4 に減らすとする論文。 以下の構成を組み合わせることによってパフォーマンス改善を実現している。
- TRIAD-MEM: 頻出するキーを L0 に書き出さず memtable で長期間持つことによって、L0 の容量を削減・コンパクション頻度を下げる。
- TRIAD-LOG: 書き込み時に memtable と同時に書き込まれる WAL を L0 として利用することで書き込み増幅を減らす
- TRIAD-DISK: L0,L1 ブロック内でのキー重複が一定量を上回るまで L0 コンパクションを遅延させることで書き込み増幅を減らす
効果が出るワークロードは限られると思うが、特別なハードウェアを使わずに一定の効果を出していて非常に興味深い。
- https://www.usenix.org/system/files/conference/atc17/atc17-balmau.pdf
- https://www.usenix.org/sites/default/files/conference/protected-files/atc17_slides_balmau.pdf
対処法 5. MatrixKV
memtable, L0 を PMDK で開発した NVMe デバイスで保持し容量を大きく取り、L1 以降の各レベルサイズを非常に大きくすることによって、書き込み増幅・ストールを減らすとする論文。
書き込み増幅とストールはコンパクション時に発生し、その多くが容量の小さい L0,L1 のコンパクションが原因となっている。 この論文では、RocksDB でのデフォルトの大きさが数十 MB 程度の memtable,L0 を合計 8GB 程度まで大きくしてコンパクション頻度を減らし、書き込み増幅と書き込みストールを同時に減らしている。 単に L0 を大きくすると読み取りパフォーマンスが大幅に下がるので、新規開発した NVMe デバイス上で動作するカラムナストレージ等を用いてパフォーマンスを維持している。
- https://www.usenix.org/system/files/atc20-paper159-slides-yao.pdf
- https://www.usenix.org/system/files/atc20-yao.pdf
まとめ
- LevelDB,RocksDB で採用されている LSM Tree は、基本的に読み取りが多いワークロードに適したデータ構造
- 書き込みが多いワークロードにおいては、書き込み増幅・ストールが問題になる
- 回避策として LSM Tree ではない Universal Compaction の利用・高速で大容量な memtable,L0 を利用する・書き込み頻度が高いキーを L0 へ書き出さない等の方法が研究されている