uWSGI環境でのprometheus_clientのMultiprocess Mode設定
PythonアプリケーションにPrometheus Exporterを組み込む際に利用する公式ライブラリ prometheus_client と、uWSGI環境での組み合わせが微妙に難しく、あまりネット上に情報が多くなかったので整理します。
この記事は さくらインターネット Calendar 2025 6日目の記事です。 さくらインターネット Advent Calendar 2025
client_python Multiprocess Mode
例えばGoやJavaアプリケーションにおいてはマルチプロセスで運用することはあまり多くなく、基本的にプロセスをまたいでメトリクスを集計する必要はありません。しかしながら、PythonのWebアプリケーションサーバーとしてよく使われるGunicornやuWSGIはマルチプロセスで動作することが多いため、プロセスをまたいでCounter,Gauge, Histogramなどのメトリクスを集約してから /metrics で内容を返す必要があります。
このプロセスをまたいで集約するという機能がprometheus_clientのMultiprocess Modeです。
Multiprocess Mode では、
- 各ワーカープロセスは自分専用のメトリクス状態をメモリマップドなファイル(mmap)として書き出す
/metricsを返すプロセスは、そのディレクトリ内のすべての.dbを読み、集約した値をエクスポートする
という動きをします。
Multiprocess Modeの設定
-
環境変数
PROMETHEUS_MULTIPROC_DIRを設定export PROMETHEUS_MULTIPROC_DIR=/tmp/prometheus_multiproc rm -rf "$PROMETHEUS_MULTIPROC_DIR" mkdir -p "$PROMETHEUS_MULTIPROC_DIR"- このディレクトリは、基本的にプロセス起動単位で毎回空にしておく
prometheus_clientのバージョン間で互換性がなかったりするので都度、空にするのが無難
-
/metricsでメトリクスを公開from prometheus_client import multiprocess from prometheus_client import generate_latest, CollectorRegistry, CONTENT_TYPE_LATEST def metrics_app(environ, start_response): registry = CollectorRegistry() multiprocess.MultiProcessCollector(registry) data = generate_latest(registry) status = '200 OK' headers = [ ('Content-Type', CONTENT_TYPE_LATEST), ('Content-Length', str(len(data))), ] start_response(status, headers) return [data]django_prometheusなどのライブラリを利用する場合は、ライブラリがエンドポイントを公開するのでこの記述は不要
-
Gunicornの場合はchild_exitフック
# gunicorn.conf.py from prometheus_client import multiprocess def child_exit(server, worker): multiprocess.mark_process_dead(worker.pid)- Gunicornはワーカープロセス終了時に
child_exitフックを呼び出す - 終了したワーカーのPIDを
mark_process_deadに渡すことで、終了したワーカーのGauge系メトリクスを削除
- Gunicornはワーカープロセス終了時に
公式ドキュメントではこのように紹介されていますが、uWSGIでは child_exit は存在しません。
また、 multiprocess.mark_process_dead で削除されるのは、Guageメトリクスのファイルのみです。
PROMETHEUS_MULTIPROC_DIR の .db ファイル
Multiprocess Mode を有効にすると、PROMETHEUS_MULTIPROC_DIR 以下にファイルが生成されます。
counter_12345.dbhistogram_12345.dbgauge_all_12345.dbgauge_livesum_12345.dbなど
デフォルトでは、ここで末尾の数字がPIDとなっています。
/metrics へアクセスした際に呼び出されるMultiProcessCollectorは *.db を全部読む必要があります。
def collect(self):
files = glob.glob(os.path.join(self._path, '*.db'))
return self.merge(files, accumulate=True)https://github.com/prometheus/client_python/blob/v0.23.1/prometheus_client/multiprocess.py#L156-L158
つまり、「一度でも存在した PID に対して .db ファイルが作られると、明示的に削除をおこなわない限り限り常に集約対象になり続けるという挙動になります。
uWSGIなどのサーバは、リソースリークなどの問題を防ぐために uwsgi --max-requests=1000 のように指定することで一定のリクエスト数毎にワーカーを定期的に再起動することが多いです。
そうなると、ワーカが生成される毎に新しいPIDが割り当てられ、そのたびに新しい .db ファイルが PROMETHEUS_MULTIPROC_DIR に生成されていきます。
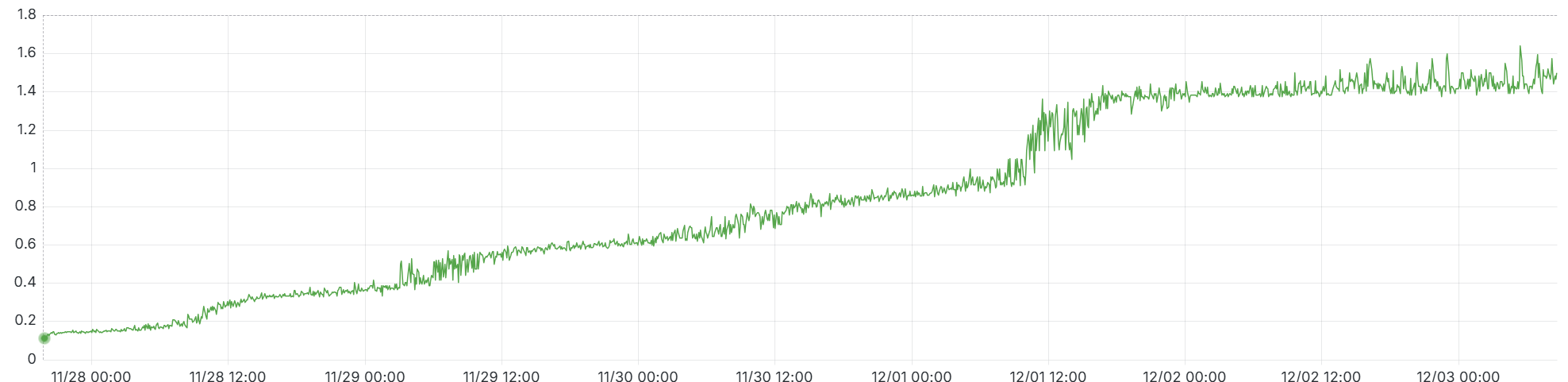
そして、大量の .db ファイルが存在する状態で /metrics にアクセスすると、すべての .db ファイルを読み込んで集約するため、非常にレスポンス時間が長くなりますし、CPU/RAM等のリソースも大量に消費します。
そしてこういう風になります。
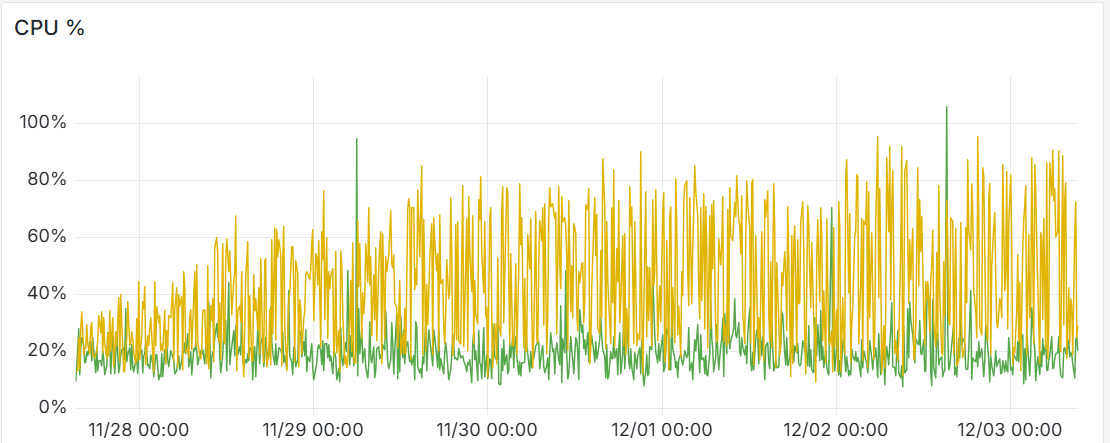
レスポンス時間もどんどん伸びてゆく。
MultiProcessValueのprocess_identifierにworker_idを指定する
MultiProcessValue は process_identifier という引数を取ります。
ですので、ここにPID以外の一意な識別子を渡すことで、.db ファイル名の末尾をPID以外のものに変更できます。
uWSGIには uwsgi.worker_id() という関数があり、これは「同時に動いているワーカー間で一意なID」を返します。
これを指定することで、ワーカーが再起動された際にも同じ .db ファイルを再利用できるようになります。
# app/wsgi.py
try:
import prometheus_client
import uwsgi
prometheus_client.values.ValueClass = prometheus_client.values.MultiProcessValue(
process_identifier=uwsgi.worker_id,
)
except ImportError:
pass # not running in uwsgi
from django.core.wsgi import get_wsgi_application
application = get_wsgi_application()これは django-prometheus 側のドキュメントにひっそりと記述されていました。
https://github.com/django-commons/django-prometheus/blob/v2.4.1/documentation/exports.md
そして注意が必要なのは、 get_wsgi_application() より前にこの差し替えを行う必要がある点です。
これより後に記述すると、タイミングによってPID/worker_idが混在することがあります。
トレードオフ
察しの良い方はお気づきかと思いますが、この方法にはいくつかトレードオフが有ります。
まず最初に、Gauge系メトリクスの意味合いが変わります。
Gunicornの child_exit フックのように、ワーカー終了時に mark_process_dead を呼び出すことができないため、古いワーカーに紐づくGauge系メトリクスを削除することができません。
live系のGaugeメトリクスは、ワーカーが再起動されても値が残り続けることになります。
そして、prometheus_clientはメトリクスの削除をサポートしていないようです。
定期的に .db ファイルをクリアする方法ですと、そのタイミングで掃除されてハッピーなんですが、Worker IDベースで作成した.dbファイルをずっと使うという事であれば、ファイルの肥大化について気を使う必要がありそうです。
DjangoでPrometheus exporter実装している人すくないな?と思ったんですが、理由が少し分かった気がしました。