コードを書かずに大量のWebサイトから内容を抽出する
業務・趣味問わず発生する「Web ページから値を拾ってきて Excel シートにコピペする」という仕事をなんとか省力化出来ないかを検討してみる。 自分は怠惰なので出来るのであればコードも書きたくない。
前提条件
- 1 つの EC サイトの商品ページ URL が 50 程度与えられる
- それぞれの価格情報を取得して Excel 等に出力する
Google Spreadsheet
よくネット記事でも紹介されている IMPORTXML 関数を利用する方法。
この関数は引数に URL と、抽出する対象の位置情報を指定する。
例えば以下のように入力すると、洗濯機のページから商品名を抽出できる。
=IMPORTXML("https://kakaku.com/item/K0001373907/","//*[@id=""titleBox""]/div[1]/h2")
位置情報 XPath という文字列を使う。 これは Chrome の Developer Tools を利用することで簡単に調査が可能。
まず、Chrome でサイトを開き、調べたい文字あたりを右クリックして「検証」をクリック。
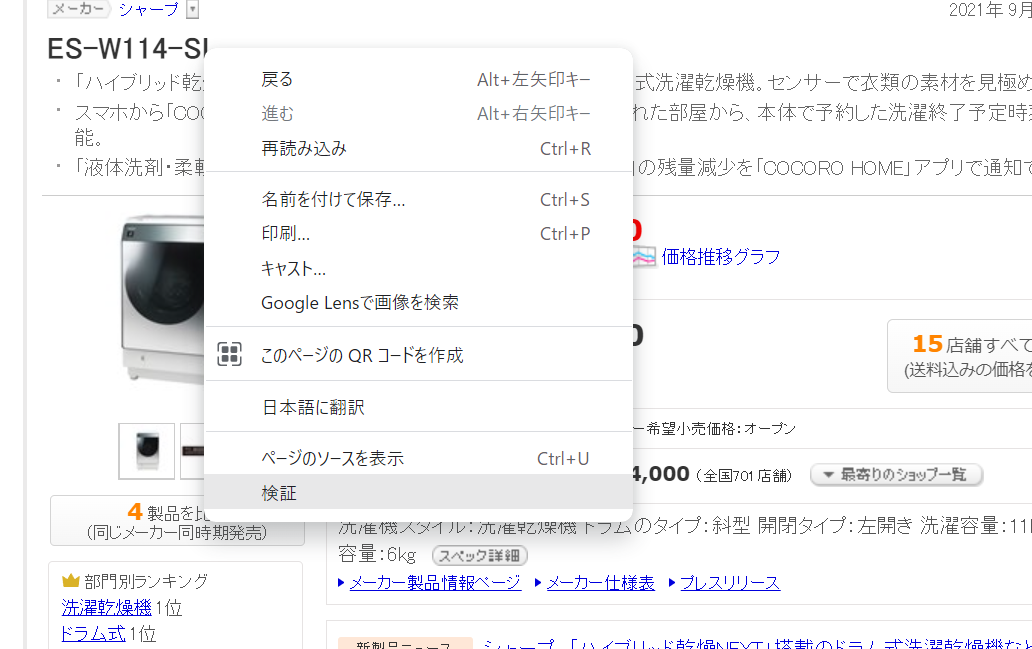
新しく開いたウインドウで青くハイライトされた箇所を右クリックし、「Copy」→「Copy XPath」をクリック。
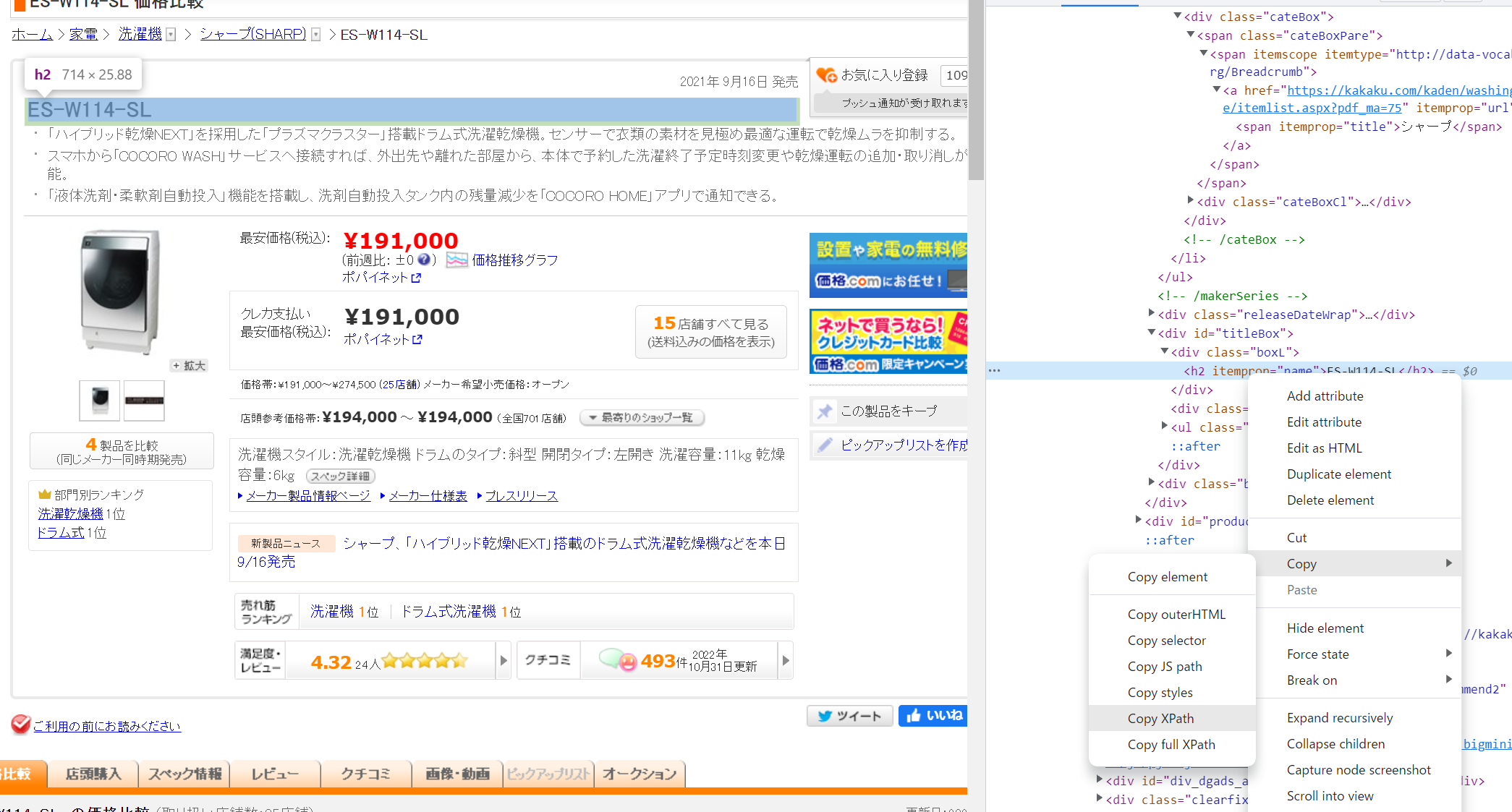
" が含まれたりする XPath を Spreadsheet に貼り付けるのは少し面倒だ。
今回は //*[@id="titleBox"]/div[1]/h2 がコピーされた。
セルに入力するときは最初に ' 文字を入れた '//*[@id="titleBox"]/div[1]/h2 と入力する必要がある。
また、関数の引数として渡すときには、以下のように " の部分を "" と書き換える必要がある。
=IMPORTXML("https://kakaku.com/item/K0001373907/","//*[@id=""titleBox""]/div[1]/h2")"あいうえお" のように " で囲まれた箇所が文字列として認識されるけど、その中に " があったらどこが終わりか分からなくなるので、終わりじゃなくて文字の " ですよと言いたいときは "" と続けて 2 回タイプする必要がある。
これを応用すれば複数のページから色んな情報もすぐに取れそうだ。早速試してみよう。
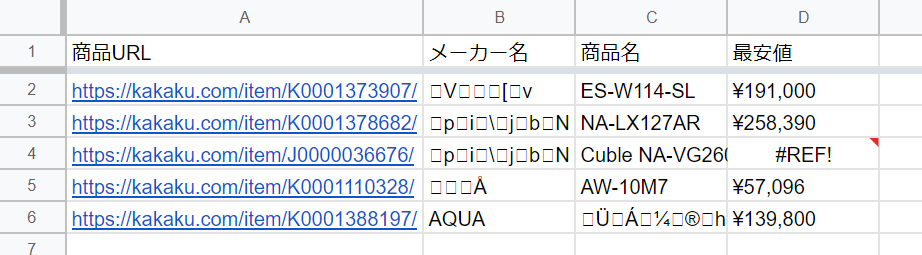
見事に日本語タイトルが文字化けしているし、4 行目の商品は若干ページの構成が違って取得が出来なかった。
IMPORTXML で日本語を取得したい場合は、文字コードが UTF-8 のサイトで有る必要がある。
まだ国内の EC サイトの多くは Shift-JIS なので、対応しておらず文字化けしてしまった。
これを修正するためにはプログラミングが必要になる。
値段が変わったときにデータの再取得を行いたいときはどうすればよいか。
便利な更新ボタンはなく、関連するセルの値が変わった時にだけ再取得が行われる。
なので、URL を全部消してから Ctrl+Z で戻せばデータの再取得が行われる。
メリット
- Google アカウントさえあれば他に何も要らない
- ある程度高速に実行される
デメリット
- サイトのデザインや構成が変わると取得できなくなる
- 日本語ページは文字化けが発生するケースも多々ある
- 再取得させるのは少し手間
- SPA(Twitter Web のようなリッチな作りのやつ)など凝ったサイトでは動作しない
- 編集履歴機能にウェブページから取り込んだ内容は記録されない
Microsoft Power Automate Desktop
Windows 上のいろんなソフトを自動操作してデータを取り出したりぶっこんだりするツール。 コードは書かないけど、少しプログラミング。
インストールするには Windows 10 以上が必要。 Microsoft Store アプリで「Power Automate」と調べるとインストールできる。 途中で Chrome の拡張機能も自動でインストールされるので許可しておく。
インストールが完了するとこんな感じの画面になるので、新しいフローをクリック。 自動化する手順の一連の流れを「フロー」として定義する。
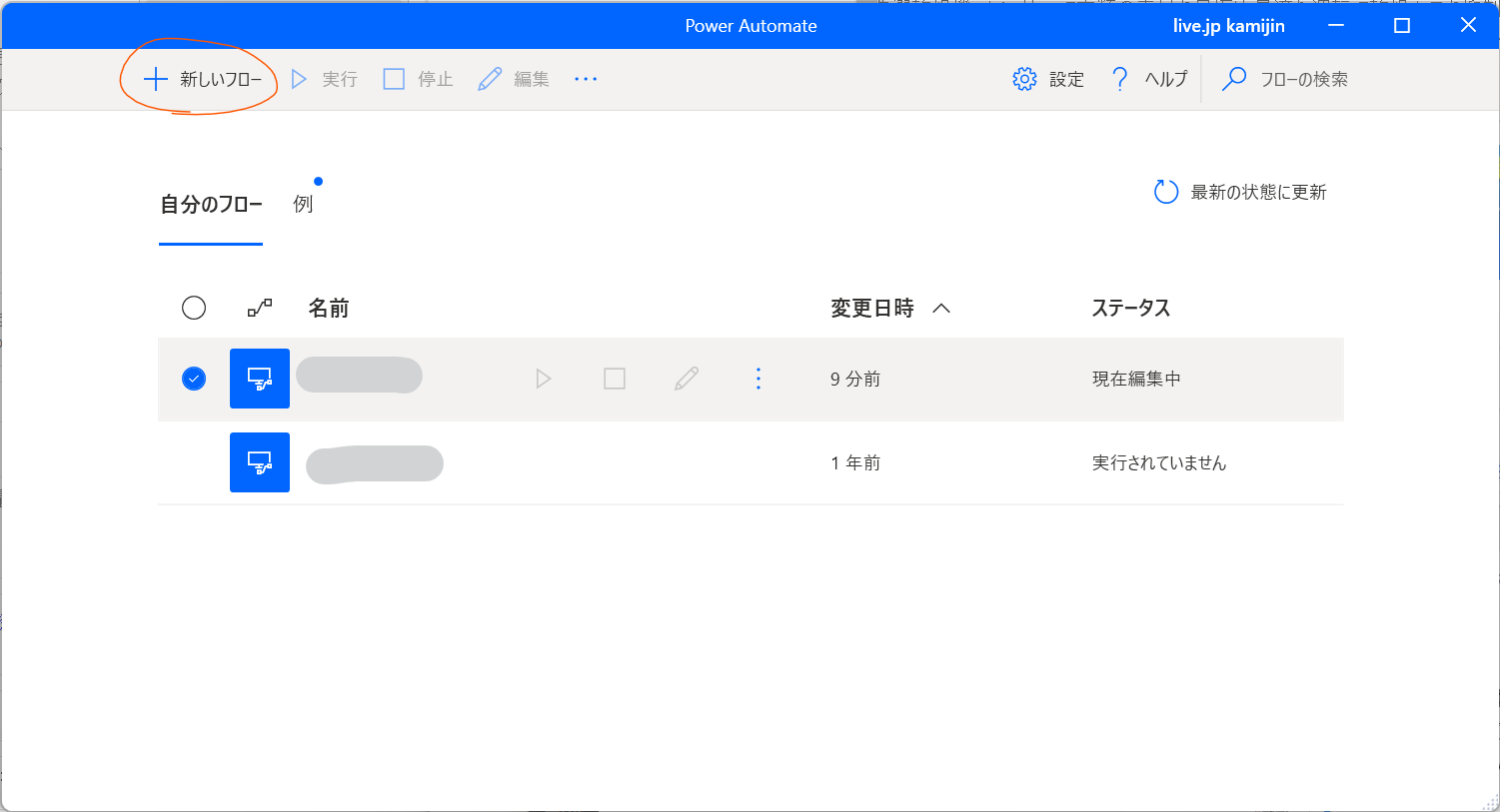
左側のアクションには色々並んでいる。 その中で選んだものをマウスでドラッグアンドドロップで真ん中に持ってくることによって使えるようになる。
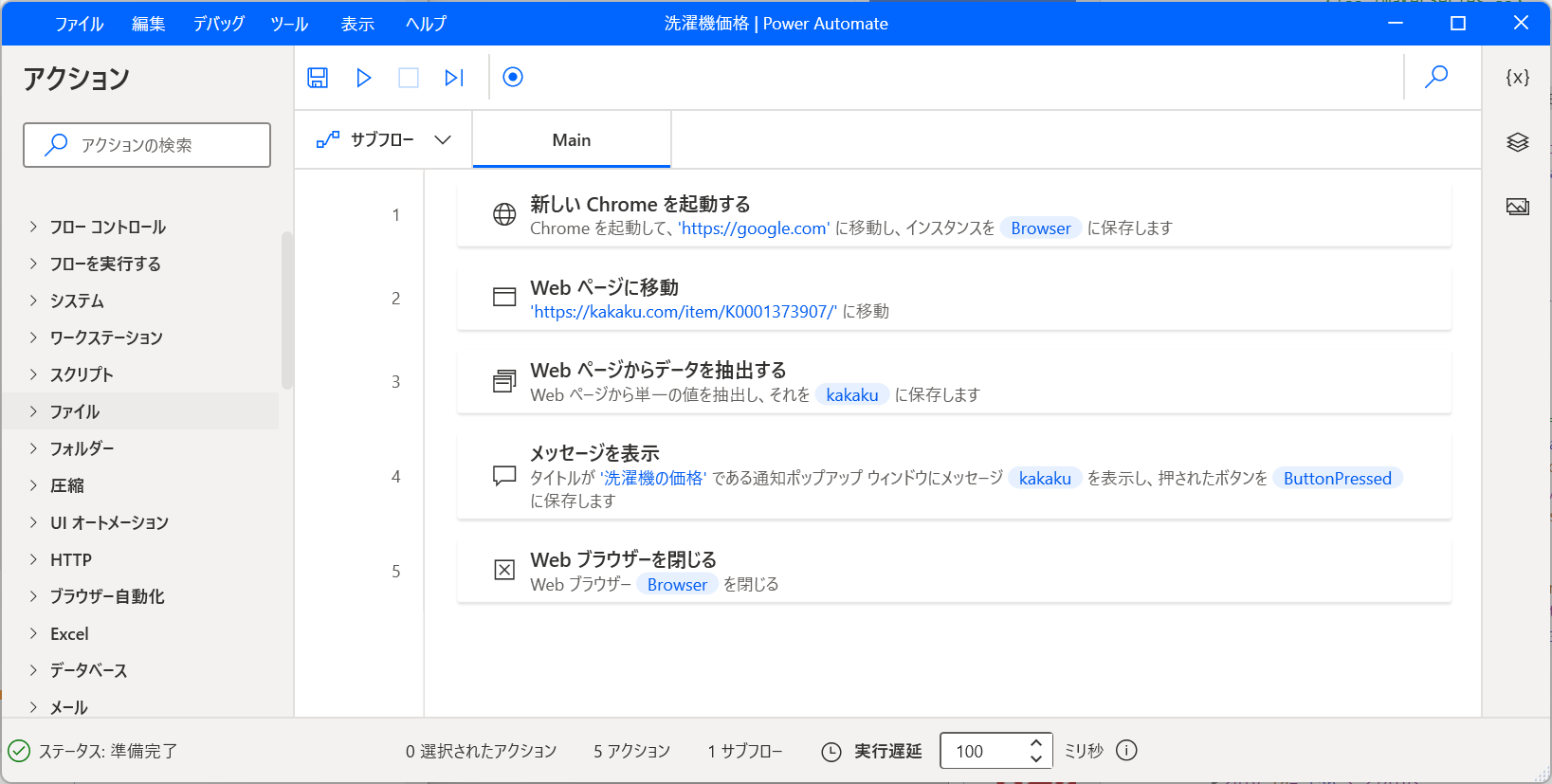
今回は ↑ の画像でやっているような、Chrome を起動して洗濯機のページにアクセスして、内容を拾ってきてメッセージを表示するというフローを作ってみる。
お試し作成
まぁまぁ手間がかかるので、まずは単純な例から。
アクションの一覧から「ブラウザ自動化」→「新しい Chrome を起動」をドラッグアンドドロップで真ん中に持ってくる。
「初期 URL」を入れないと怒られるので、適当に https://google.com/ と入れておく。
次に「ブラウザ自動化」→「Web ページに移動」を追加する。
URL には洗濯機のページ URL https://kakaku.com/item/K0001373907/ を入れておく。
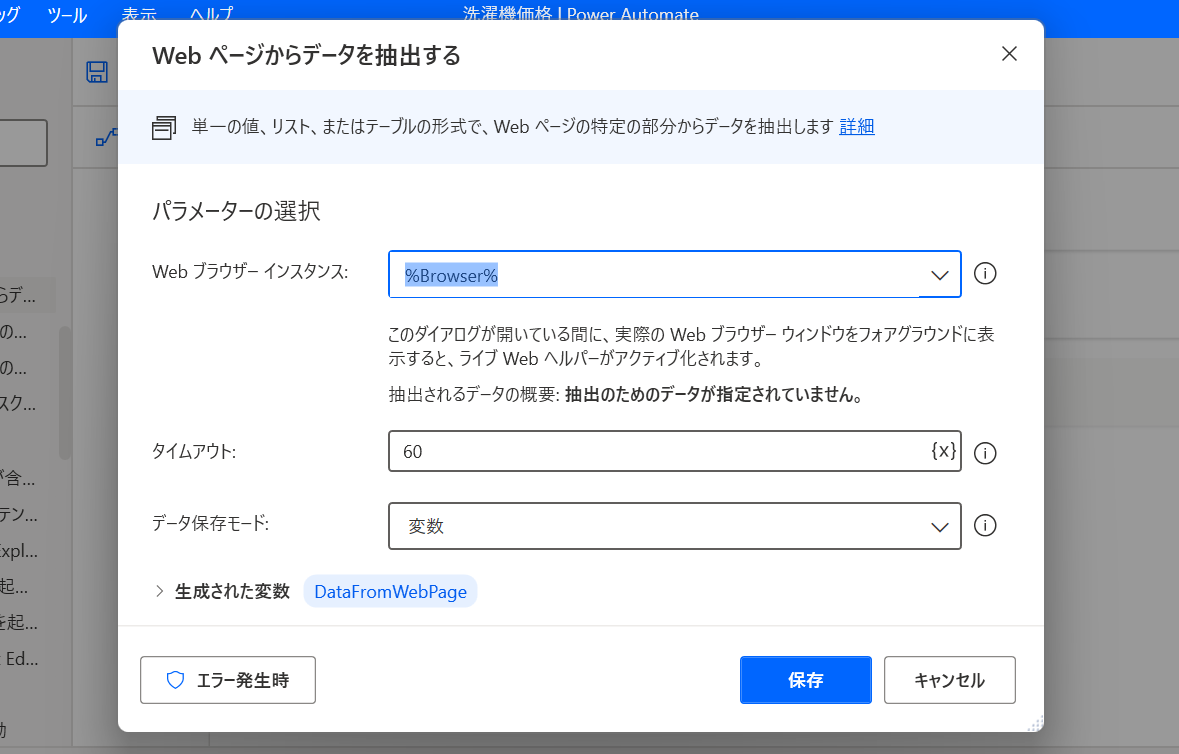
そして次に実際にページから値を抽出する。 「ブラウザ自動化」→「Web データ抽出」→「Web ページからデータを抽出する」を追加する。
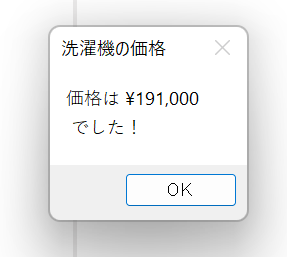
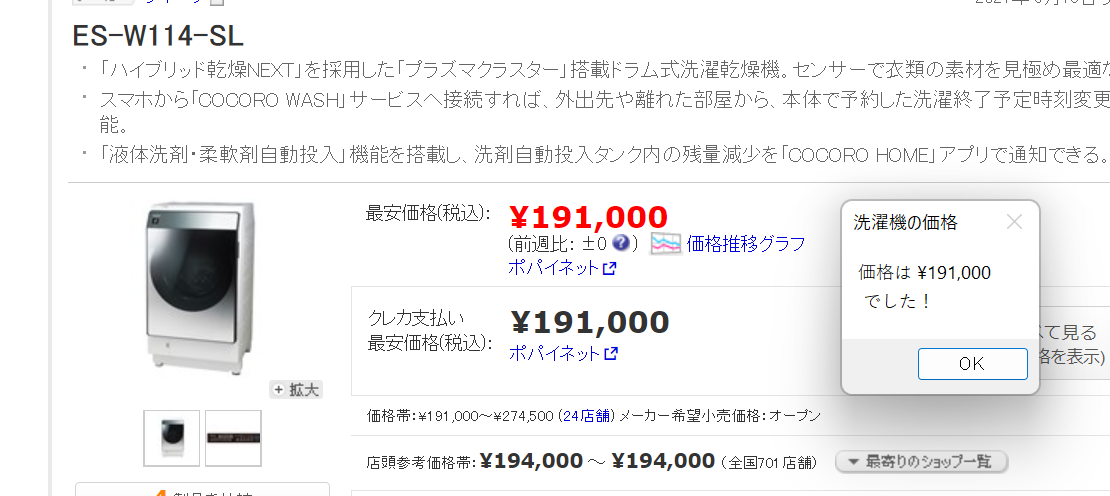
そしてこの画面を表示させたら Chrome で https://kakaku.com/item/K0001373907/ にアクセスする。 そうすると、こんな画面が出てくるので、目的の値段の部分を「右クリック」して「要素の値を抽出」→「テキスト: (’¥ 191,000’)」をクリック。
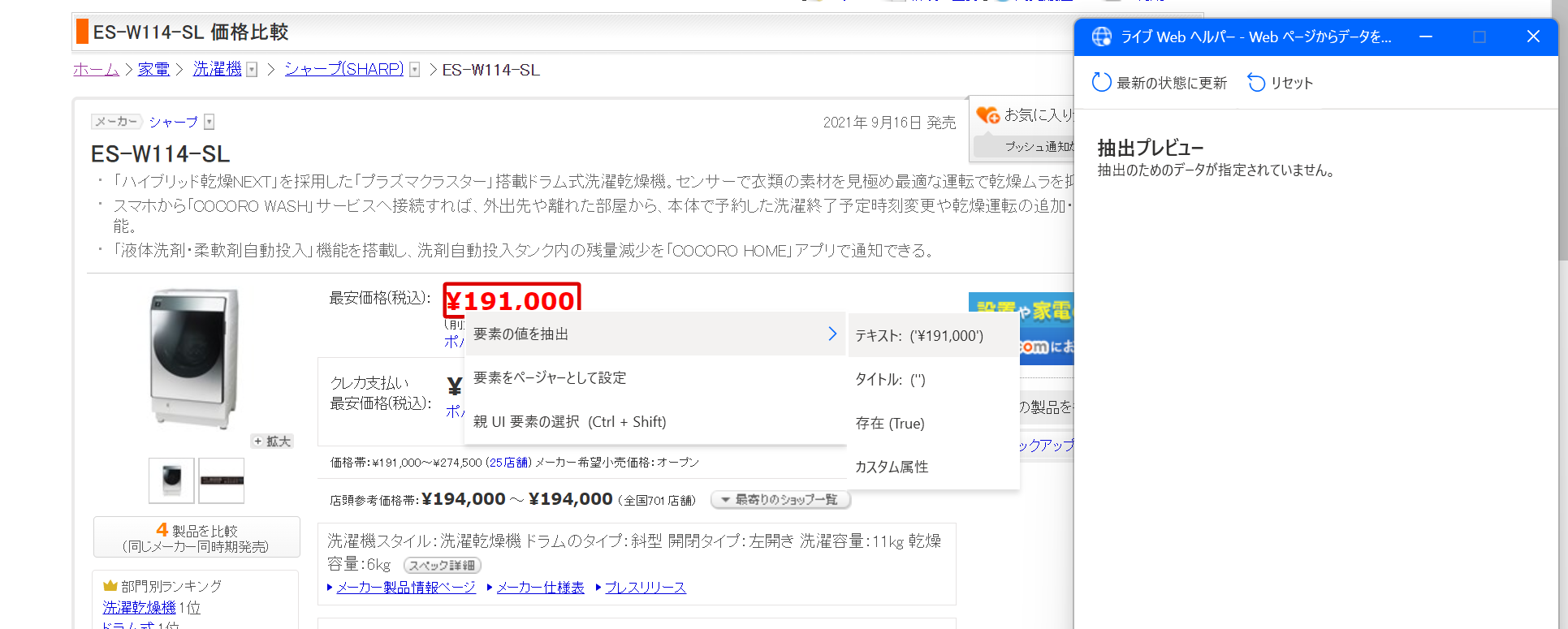
そうすると、こんな感じ抽出プレビューに値段が出てくる。 これを確認して「終了ボタン」をクリック。
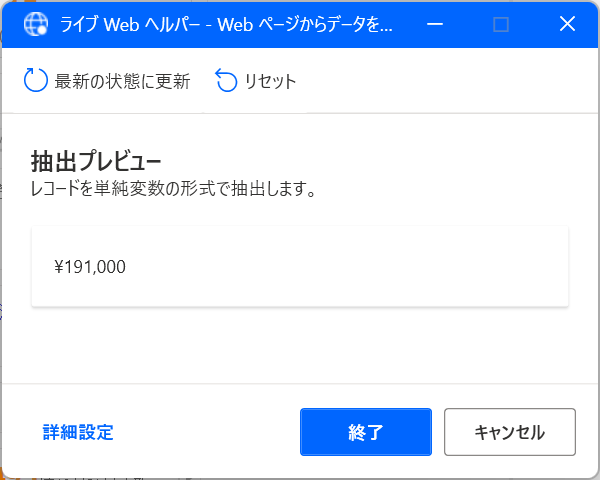
元の画面に戻ってきたら「生成された変数」を適当に何回かクリックして %kakaku% と入力。
そして保存をクリック。
さっき抽出した ¥191,000 という値は %kakaku% という変数(箱)にぶっこまれる。
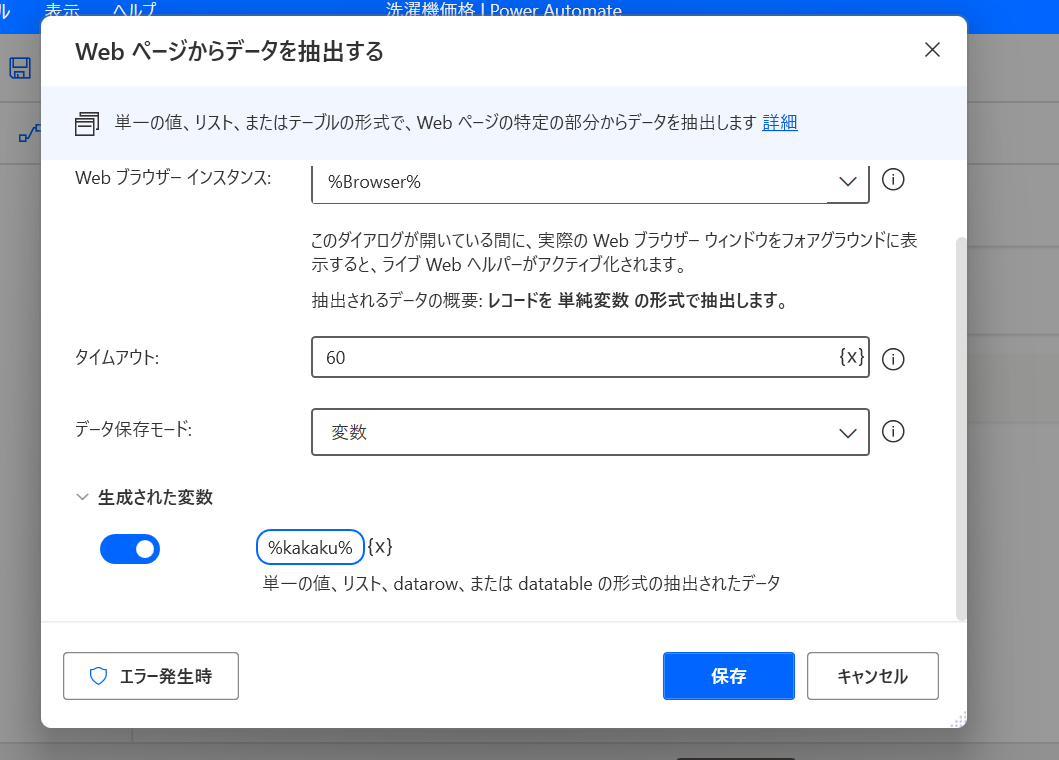
次にさっき保存した %kakaku% を表示してみよう。
「メッセージ ボックス」→「メッセージを表示」アクションを追加する。
「表示するメッセージ」に 価格は %kakaku% でした! と入力する。
そして保存。
ちなみに、使える変数は入力欄右側の {x} のアイコンをクリックすると出てくるので、ミスが怖い場合はこれを使うと良い。
そして最後は「ブラウザ自動化」→「Web ブラウザーを閉じる」アクションを追加。 特に何もせずに保存。
完成したので上の再生ボタンをクリックして実行。
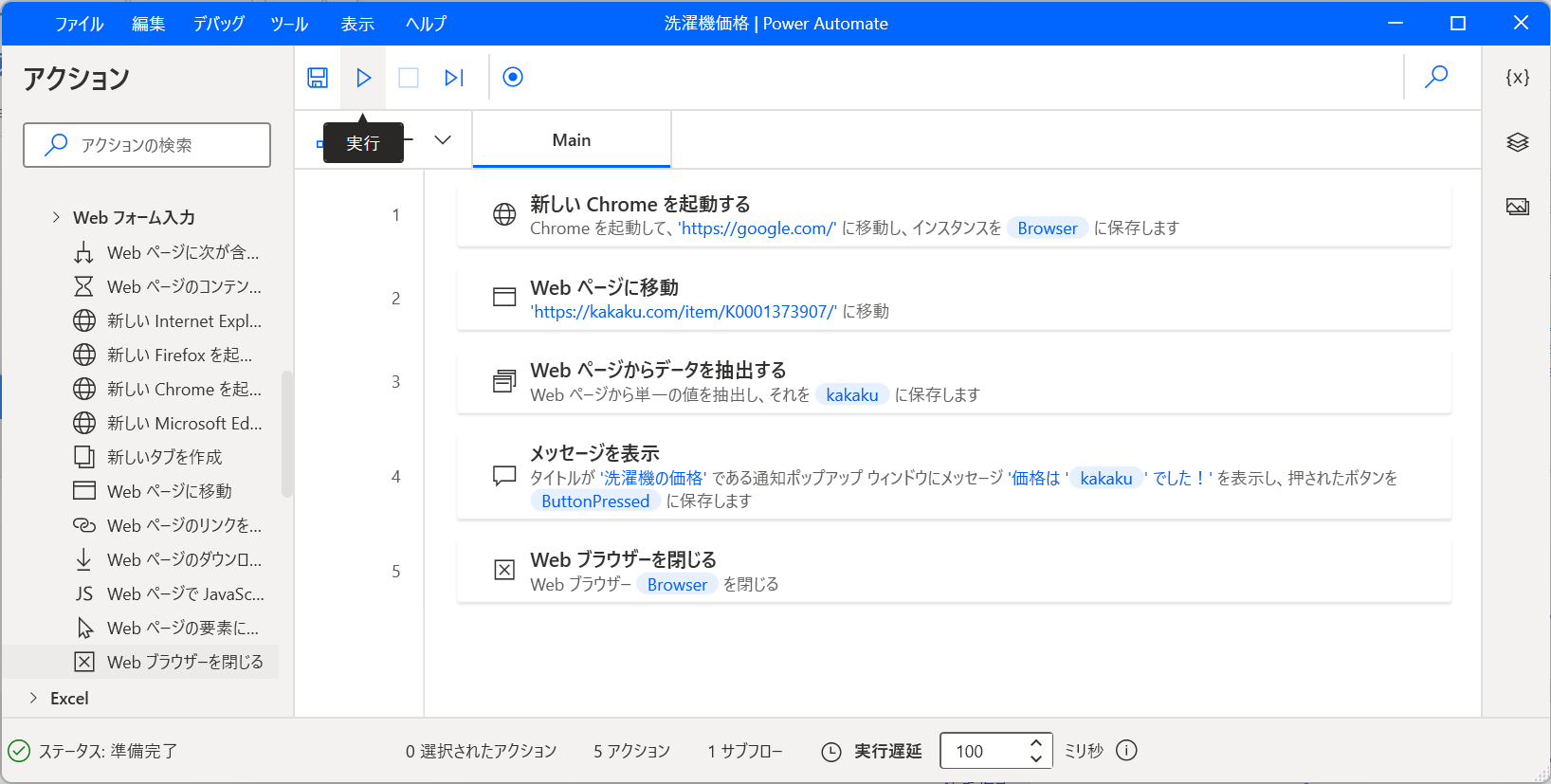
ブラウザが勝手に開いてガチャガチャやって最終的に値段が出てきたら成功。
1 つの URL にアクセスして 1 つの値だけ持ってくるフローが完成した。 次はこれを複数項目使える形に変形していく。
複数のウェブページをループさせる
こんな感じのテキストファイルをメモ帳で作ってみる。
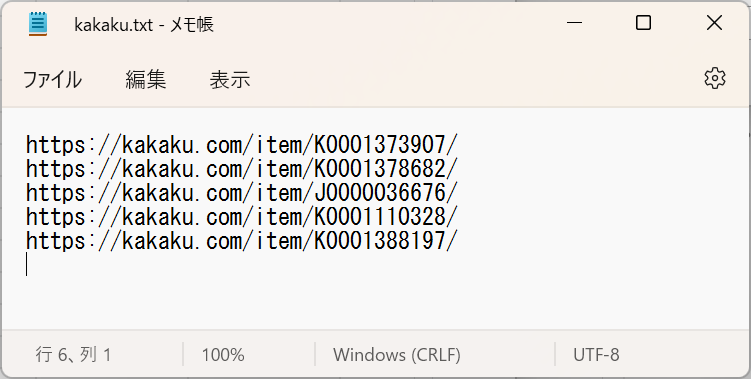
https://kakaku.com/item/K0001373907/
https://kakaku.com/item/K0001378682/
https://kakaku.com/item/J0000036676/
https://kakaku.com/item/K0001110328/
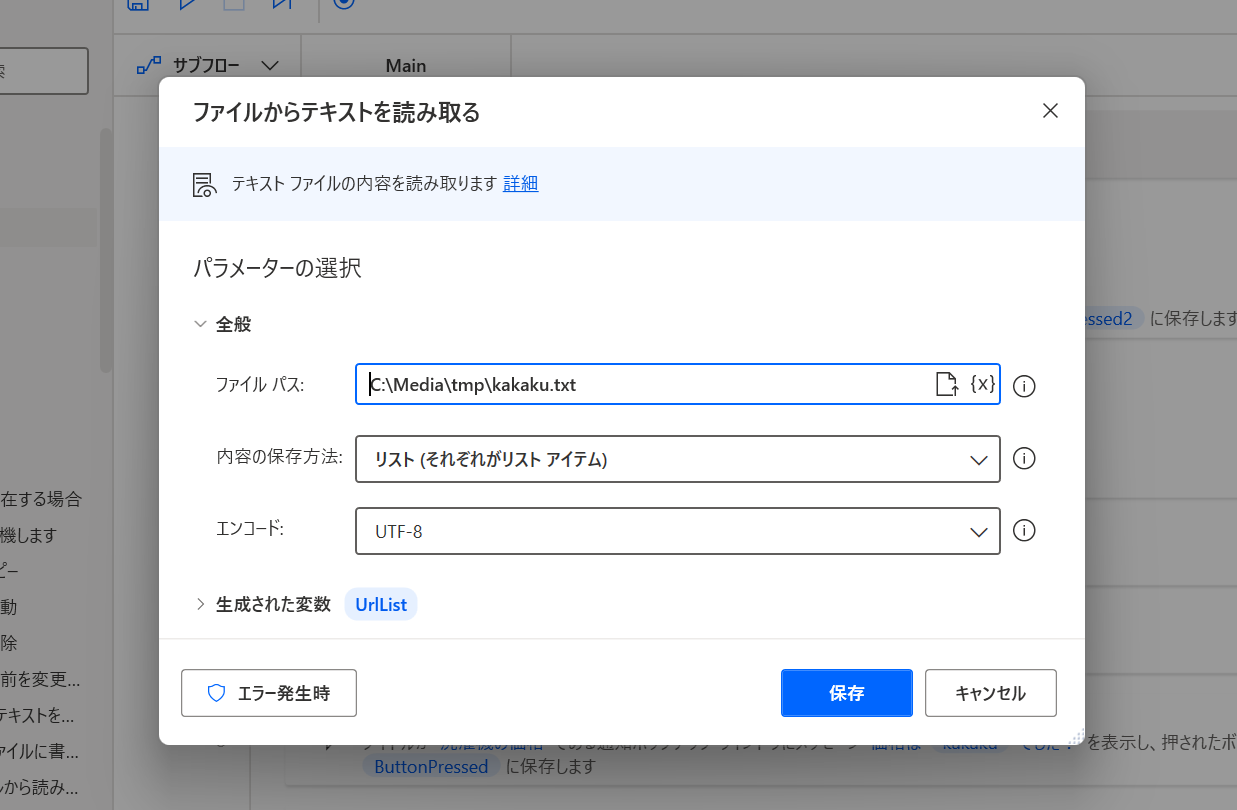
https://kakaku.com/item/K0001388197/そして作ったファイルを読み取るために、「ファイルからテキストを読み取る」アクションを先頭に追加してみる。
ファイルパスでさっき保存したファイルを選択し、「内容の保存方法」を「リスト」に変更し、「生成された変数」は %UrlList% としておく。リストに指定することによって、ファイルの一行毎にバラされた文字として扱われる。
そして次に「ループ」→「For each」を選択。
これでさっき作った %UrlList% を指定する。
保存先は何でも良いけど %url% としておく。
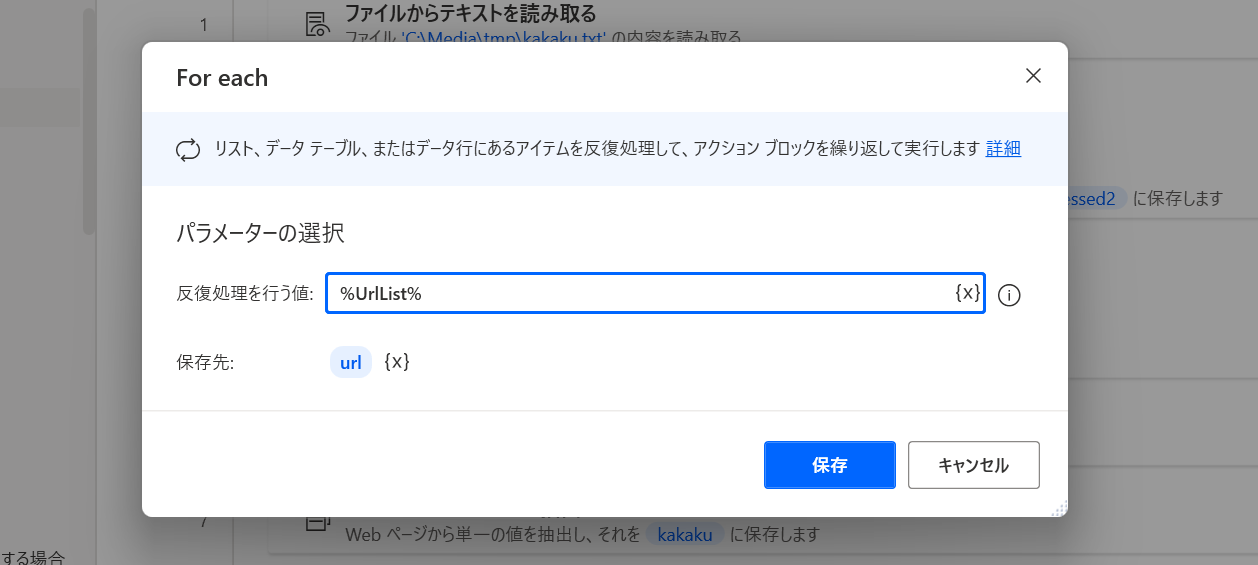
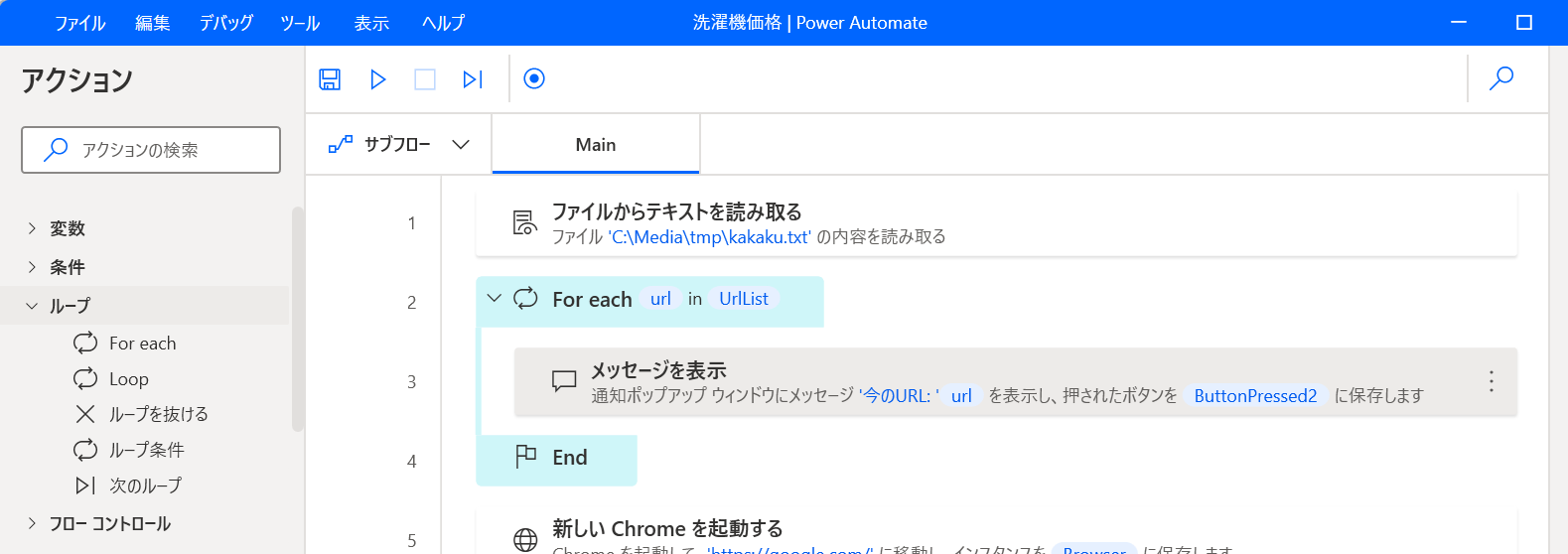
そしてループがどう動いているかを確かめるために、「メッセージ ボックス」→「メッセージを表示」アクションを追加する。
「表示するメッセージ」は 今のURL: %url% としておく。
ここまでやると、こんな感じになる。
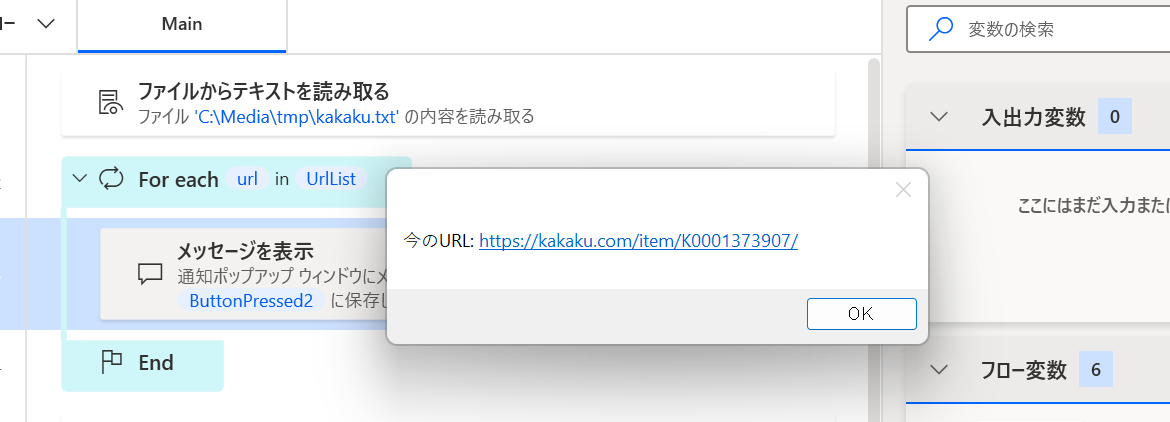
実行ボタンを押してみると、こんな感じでメッセージボックスが 5 回表示される。
このメッセージボックスを出す代わりに「Web ページに移動」「Web ページからデータを抽出する」を実行すれば良くね?ということでやってみる。
以下のような形になる。
ループさせたい処理をドラッグアンドドロップで移動させる。
「Web ページに移動」をダブルクリックして URL を https://kakaku.com/item/K0001373907/ から、ループ変数の %url% に書き換える。
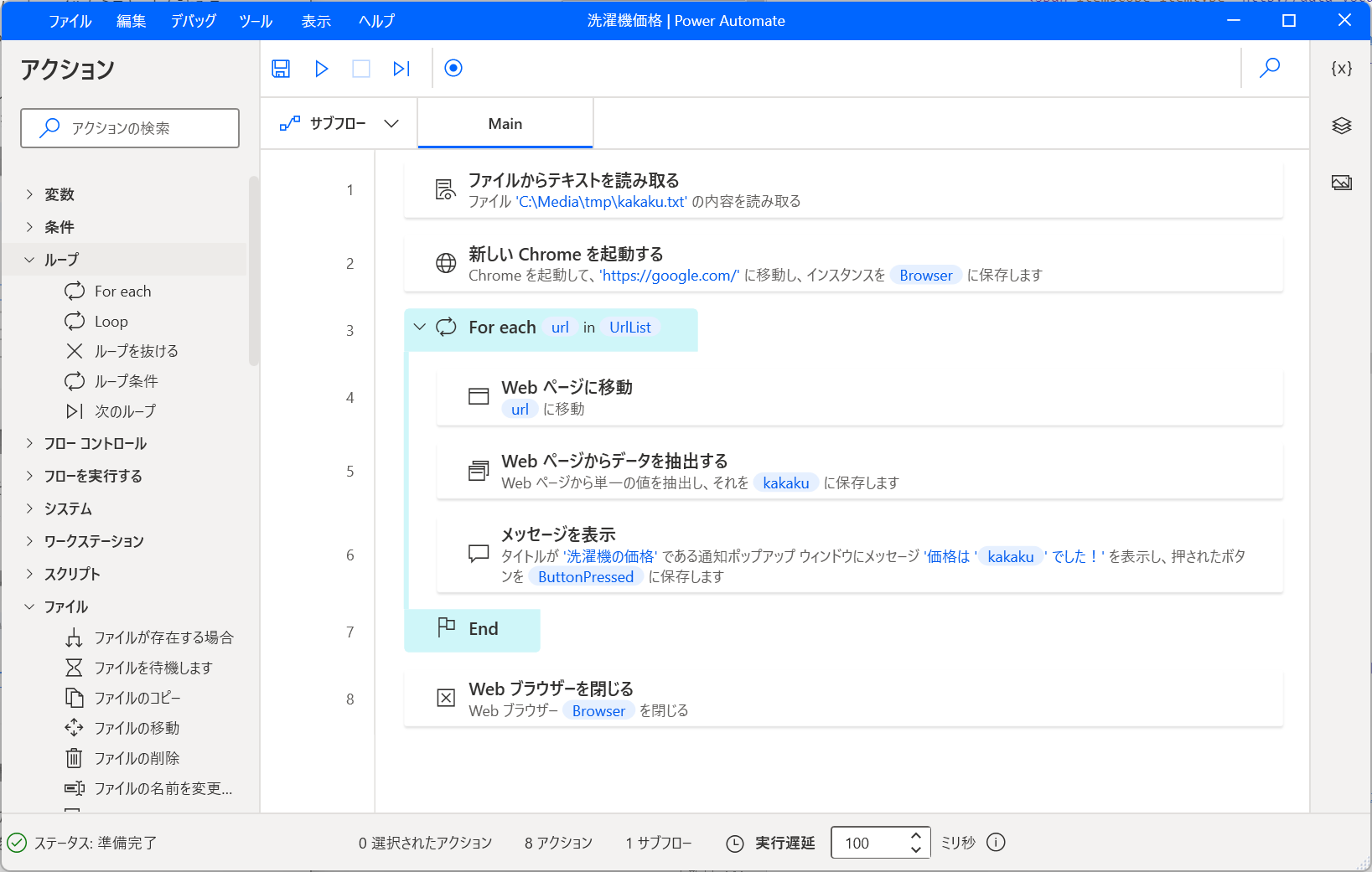
そして再生ボタンを押してみると、値段が書かれたメッセージボックスが 5 回出る。 いい感じじゃん。
結果をファイルに出力する
メッセージボックスに出ているだけだと、使い勝手が悪い。 代わりにファイルに書き出してみよう。
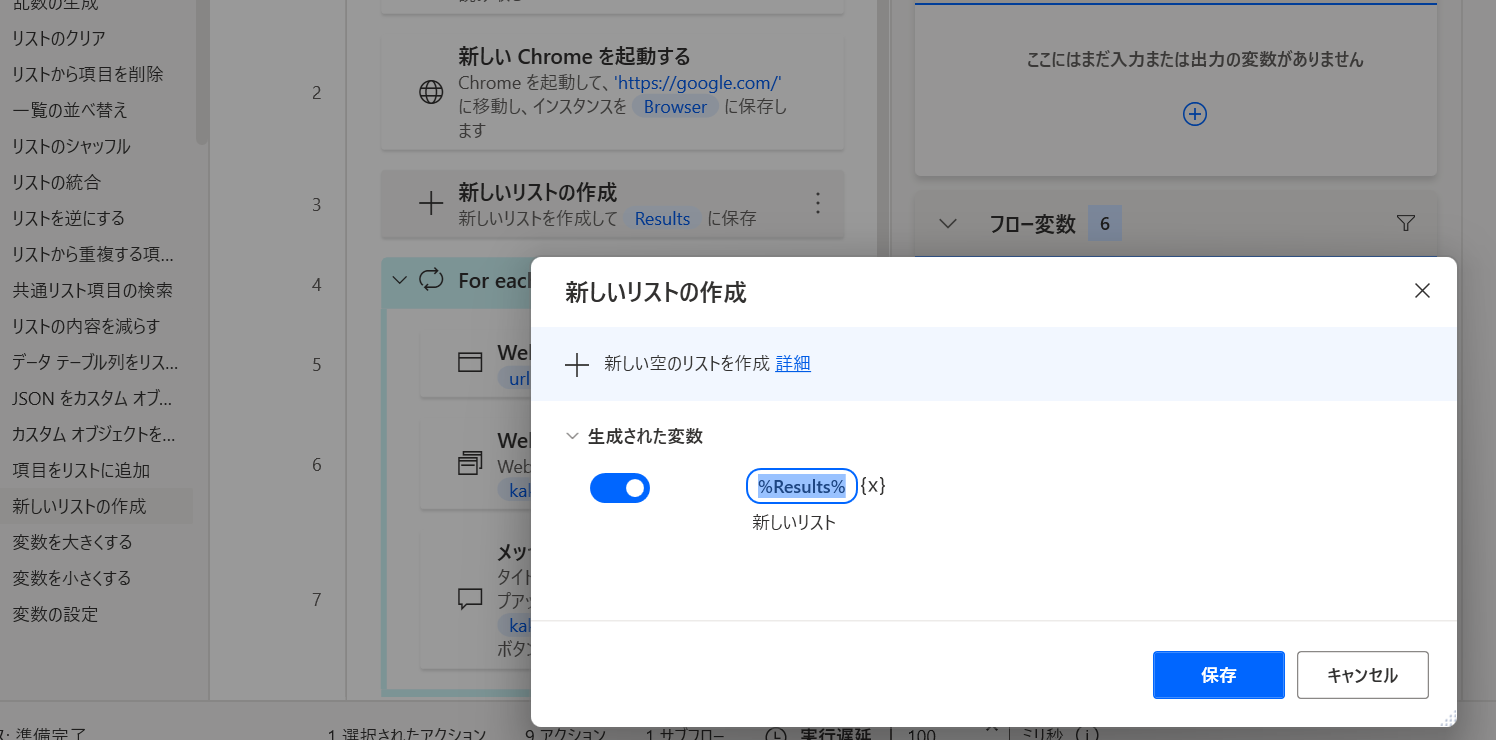
いくつかやり方があると思うけど、まずは「変数」→「新しいリストの作成」アクションを追加してみる。
名前は %Results% みたいな感じで。
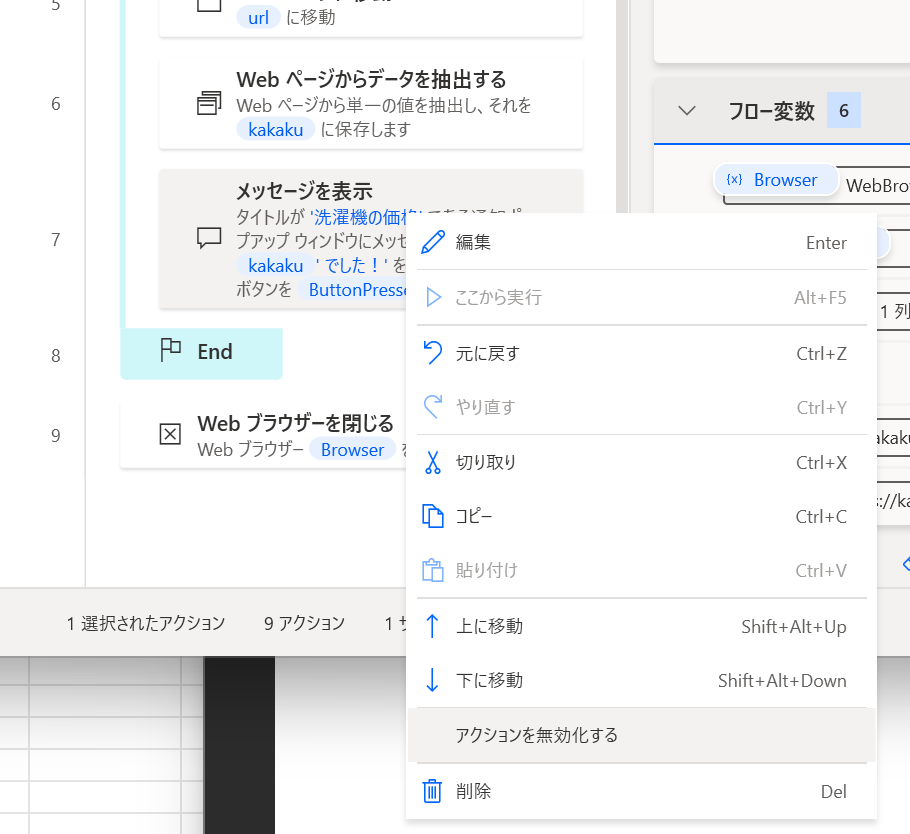
「メッセージを表示」が 5 回表示されるのは鬱陶しいので、一旦右クリックして「アクションを無効化する」をクリックしておこう。
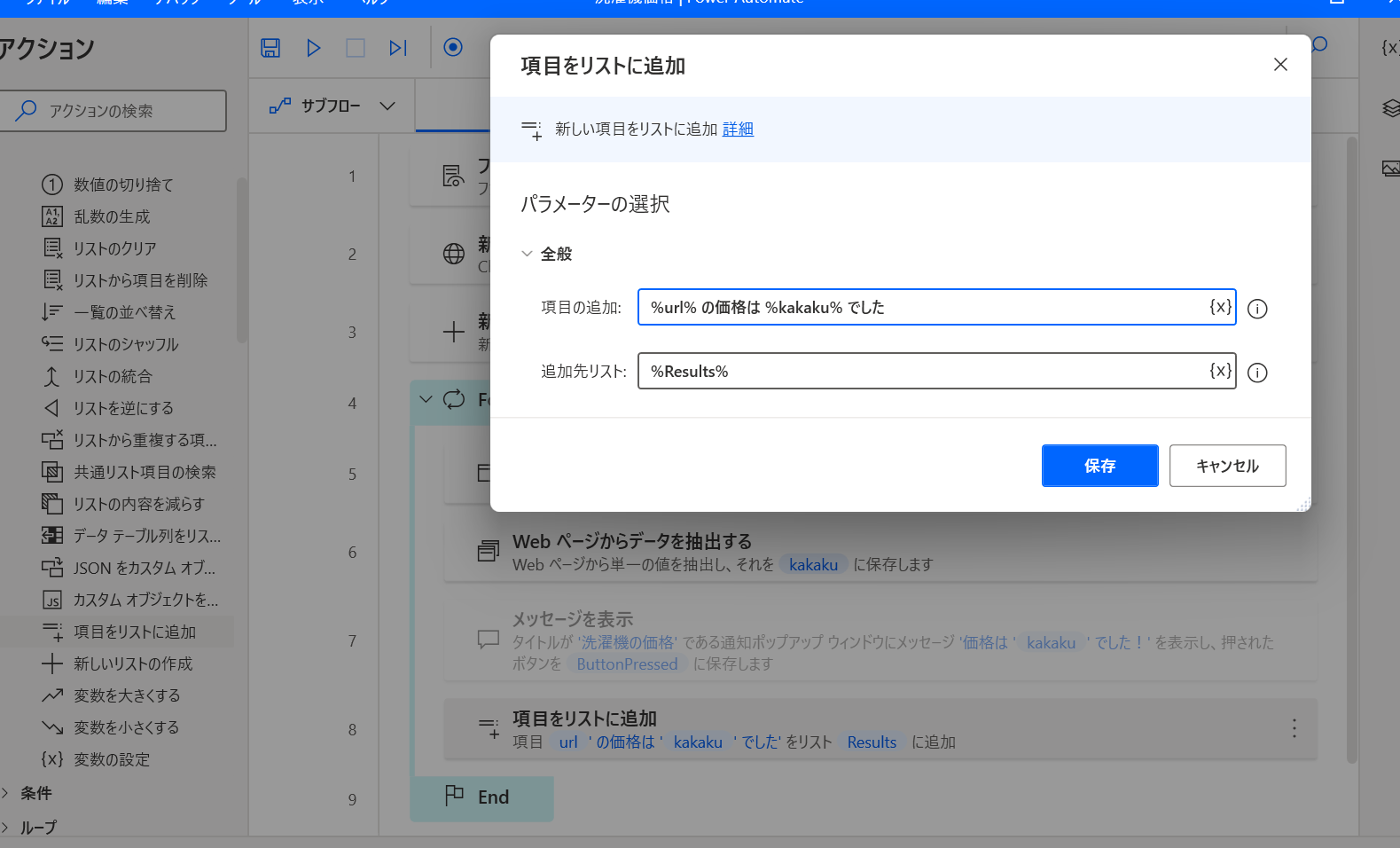
そして、「変数」→「項目をリストに追加」アクションをその下に追加する。
項目の追加が %url% の価格は %kakaku% でした 、追加先リストを %Results% としておく。
そして最後に「ファイル」→「テキストをファイルに書き込む」アクションを追加。
「ファイルパス」保存してほしいファイル名を指定して、「書き込むテキスト」は %Results% を指定する。
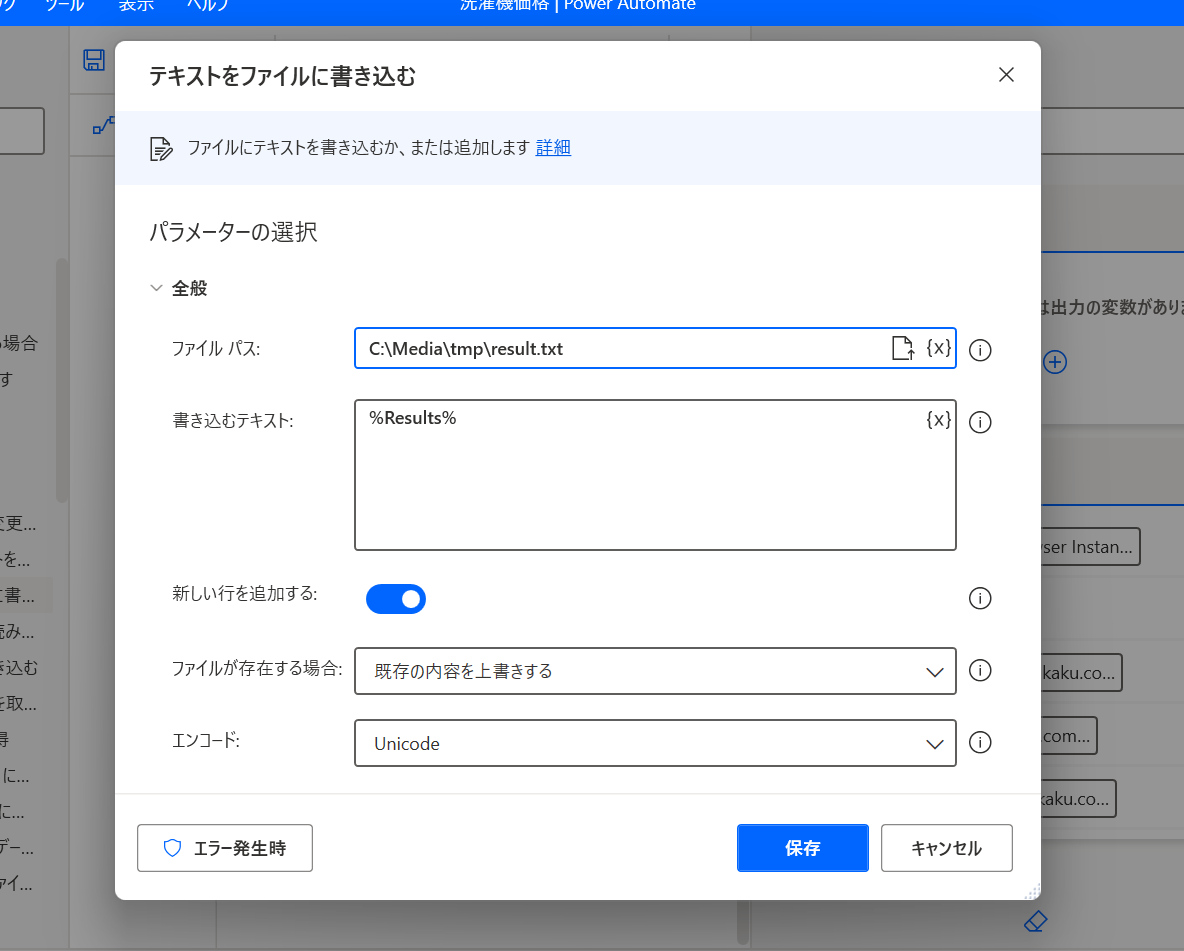
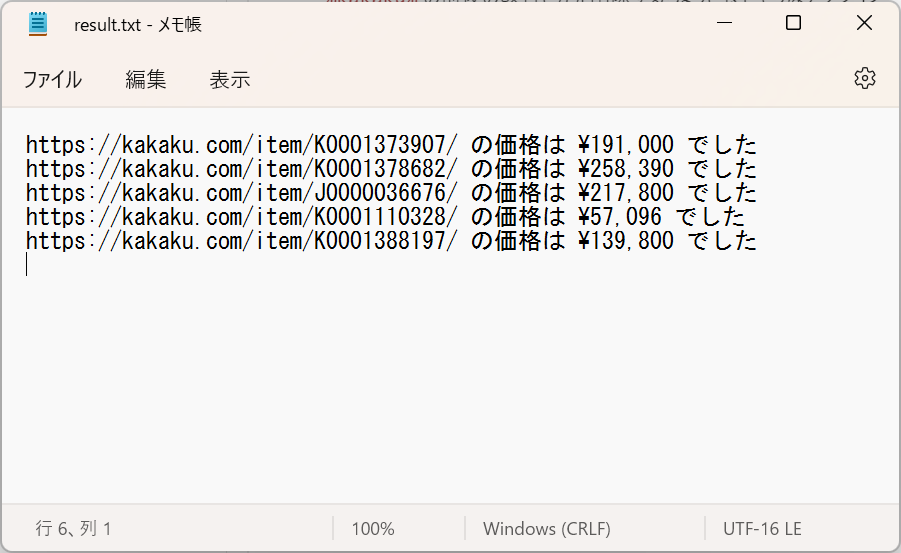
そして実行すると、こんなファイルが生成された。
うーん惜しい…! 多分価格の %kakaku% に余計な改行が入っているから変なテキストになっている。
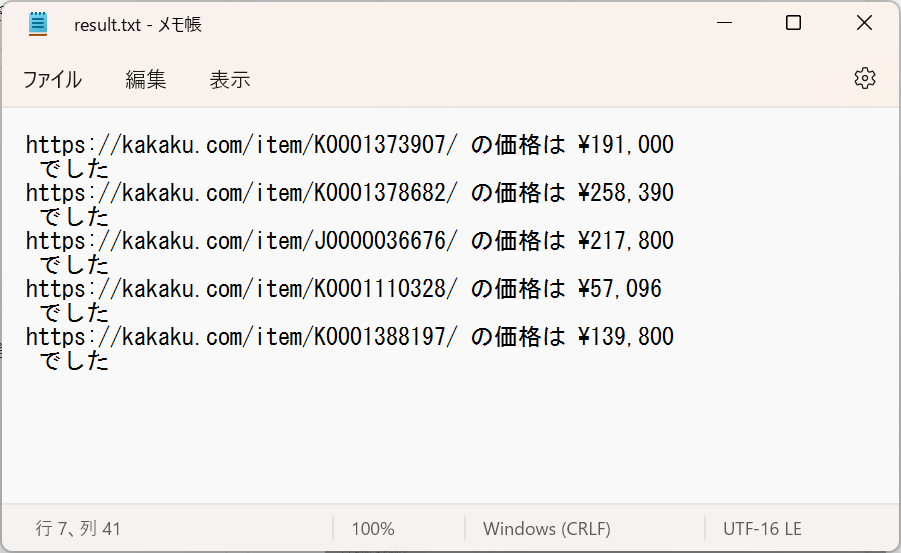
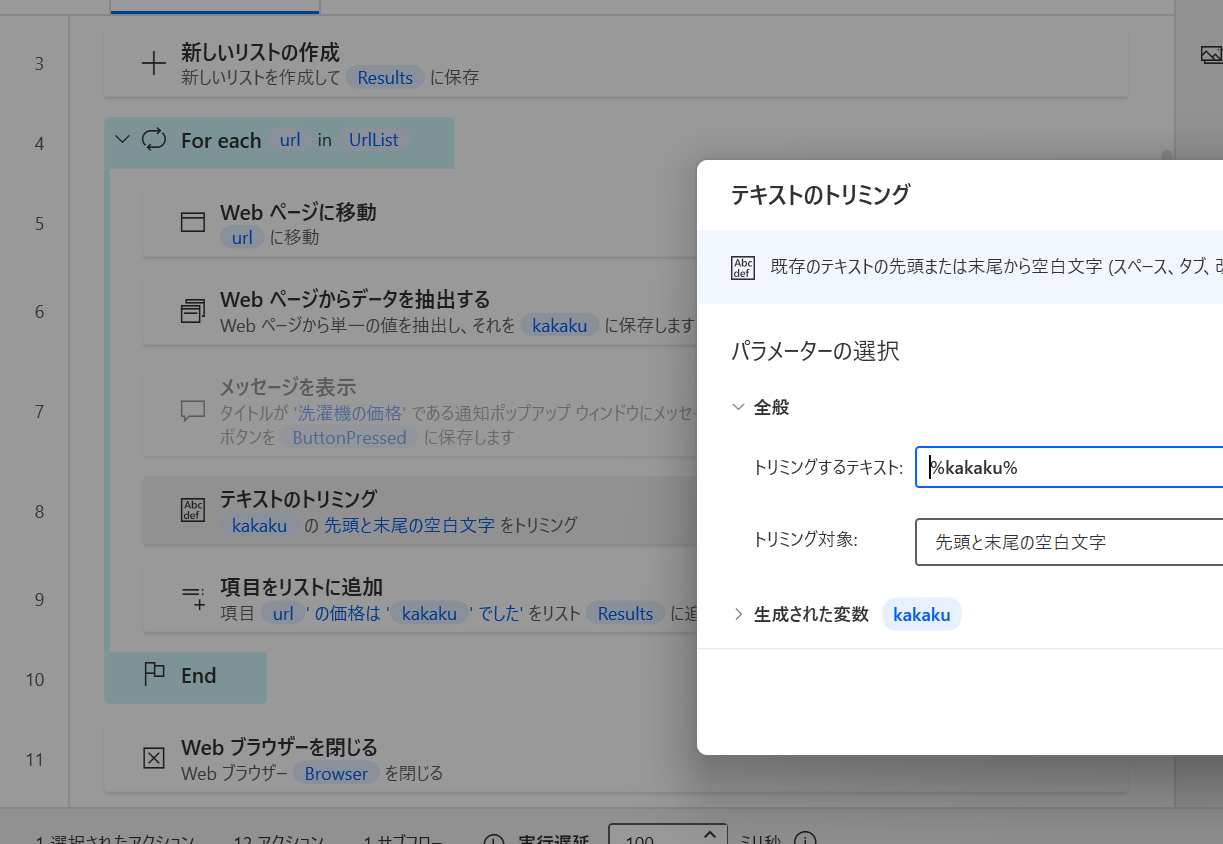
%kakaku% の前後の改行とかを削除するちょうど良さそうなアクションがありそうなので、「テキスト」→「テキストのトリミング」を追加。同じ名前のやつが 2 つあってややこしいけど、編集画面が ↓ とおなじになるやつで。
「トリミンするテキスト」と「生成された変数」の両方を %kakaku% にする。
これで前後の改行が消された文字で上書きされる。
完成形
最終的にこんな感じになりました。
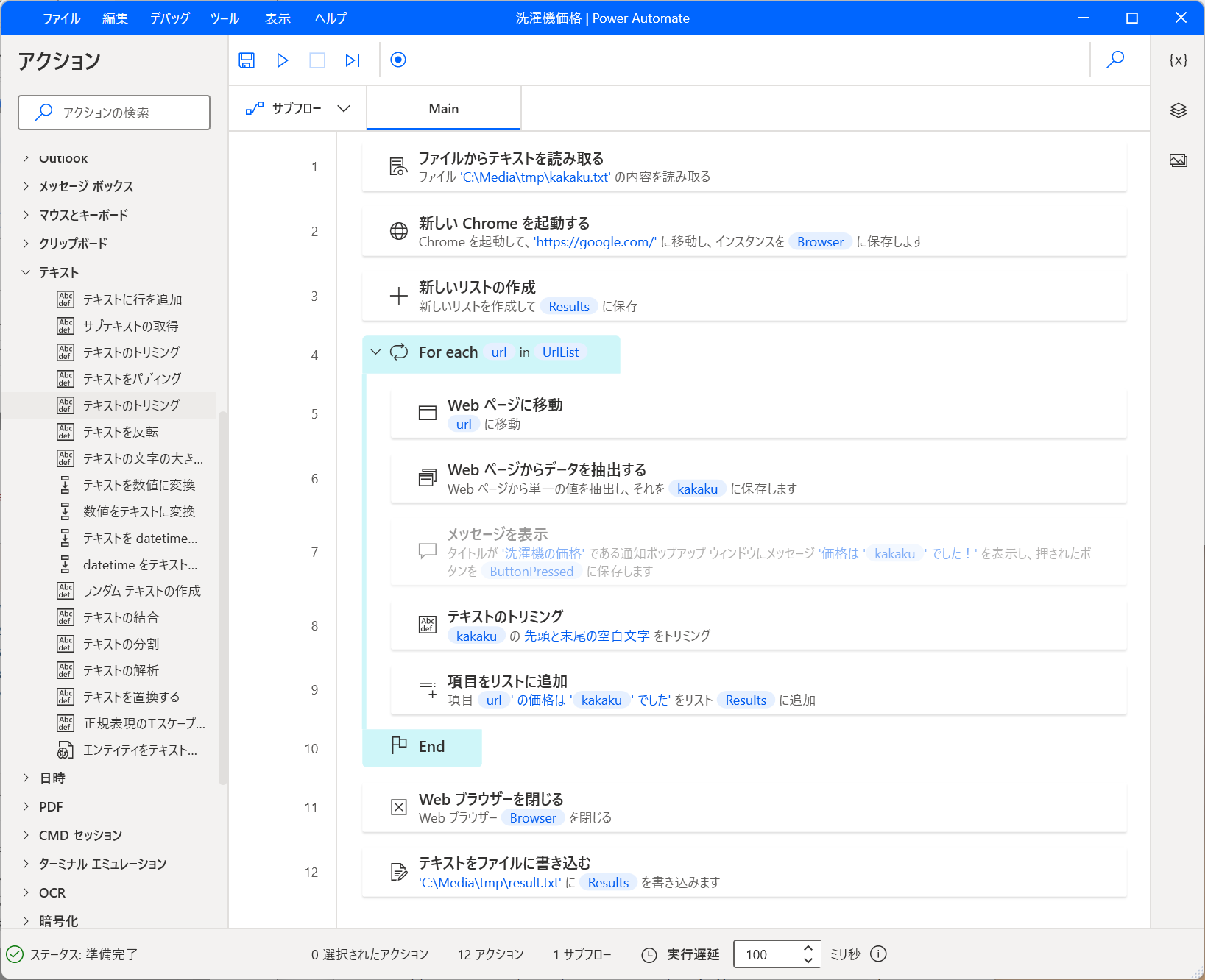
実行してみると、無事に意図した内容になっています。
今回は 1 つの価格だけを抽出しましたが、変数の名前を変えれば複数の値を抽出することも出来ますし、アクションの種類も多いので応用が効きそうです。
また、宗教上の理由で PC に Excel を入れていないので試せなかったですが、Excel の読み書きや、CSV ファイルの読み書きも出来るようです。
やっていることは完全にプログラミングですが、簡単なマウス操作でパズル感覚で遊べるので Excel のマクロ(VBA)等と比べると難易度は低めかなと思います。
メリット
- Windows 10 以上であれば無料で使える
- 複雑なウェブサイトや日本語のウェブサイトでも正常に実行できる
- 今回のケース以外にも自動化出来る処理は非常に多い
- プログラミングをゲーム感覚で学べる
デメリット
- サイトのデザインや構成が変わると取得できなくなる
- 新しめの Windows のマシンが必要
- コードは書いてないけどプログラミング
デスクトップ版とクラウド版があって、後者は有料のものしかないのでインストール時には要注意。
まとめ
- Web ページの情報取得は Google Spreadsheet を使うのが手軽だが、利用できるケースは少ない
- Power Automate は複雑な処理や Spreadsheet で取得できない内容の取得・ファイル操作なども行えて汎用的だが複雑で少し難しい