Trinoでプラグインを作って独自コネクタを作る
Trino は SQL 言語でクエリが可能なビックデータ用の分散クエリエンジンです。 meta が開発する Presto の Fork OSS プロジェクトであり、Presto は AWS Athena, Treasure Data CDP 等で利用されています。 Trino,Presto は現時点では大部分で同一の機能を持っており、いずれも HBase,Hive,ClickHouse,Elasticsearch,BigQuery,MySQL 等の様々なデータベースと接続を行った上で、透過的に JOIN を含めた巨大なクエリを実行することが出来ます。
コア開発者は全員 Trino 側の開発に移っているようです。 https://trino.io/blog/2020/12/27/announcing-trino.html
これは頭の中で整理するために作成したクラスの関係図です。
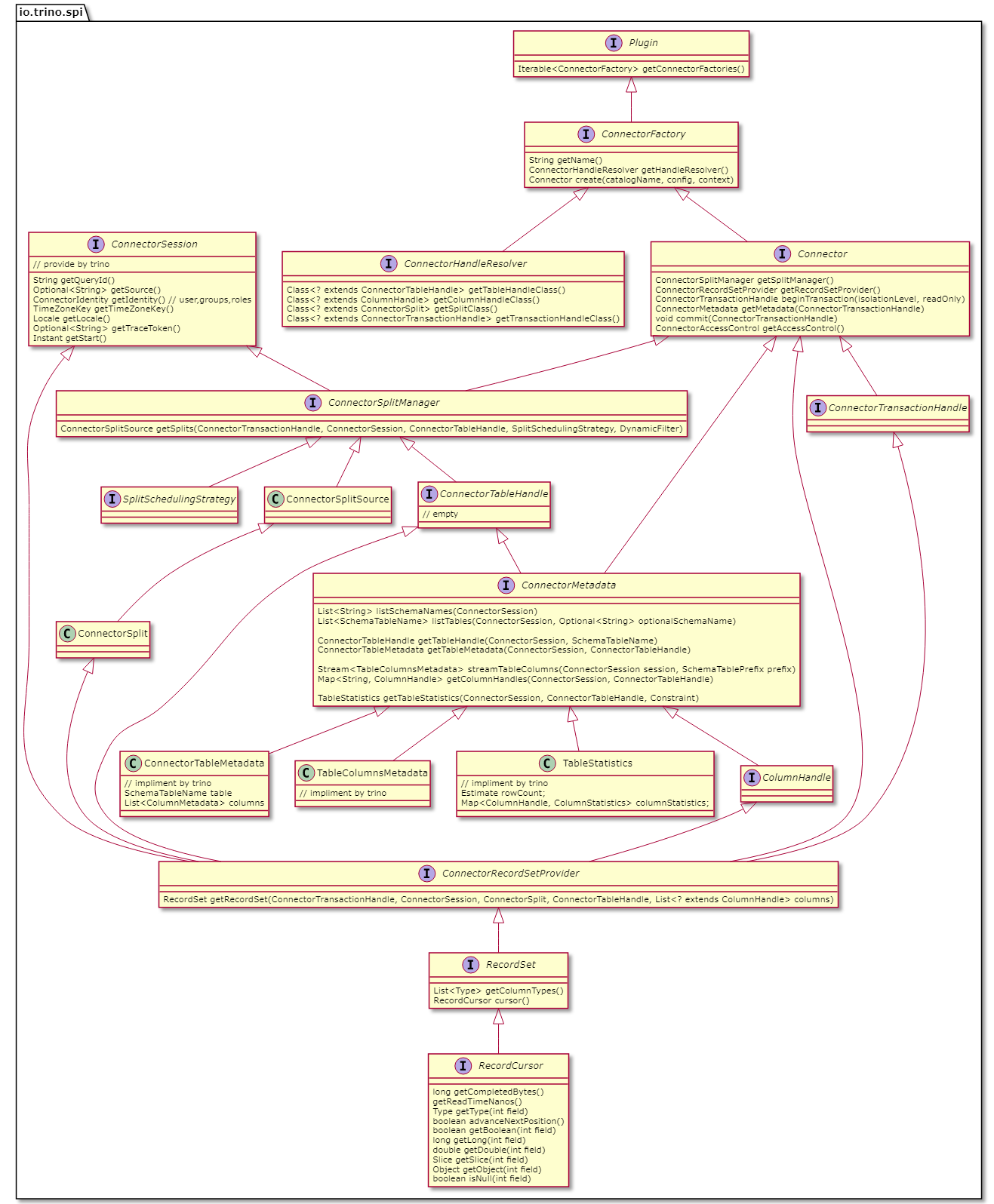
プラグイン機構
Trino にはプラグイン機構が存在し、主に以下のような物を利用ユーザが追加することが出来ます。 プラグインのインタフェースは SPI と呼ばれており、プラグインを開発する上で必要なツールや Java のライブラリが配布されています。 標準で提供されている MySQL 等のコネクタや認証認可の仕組みも、すべてkのプラグイン機構を使って実装されています。
- Connector (データソース)
- Types (データ型)
- Function (組み込み関数)
- ACL (認証及び認可)
ビルドに必要なツールは trino-maven-plugin で、Maven のプラグインとして利用することで Trino のプラグインの形としてビルドが行えるようになります。
プラグインのインタフェース定義は trino-spi という名前のライブラリとして配布されています。
プラグインの開発時に便利なクラス定義等は trino-plugin-toolkit という別のライブラリで配布されています。
trino-maven-plugin を入れた上で maven package を実行して出力される jar が数十個はいったディレクトリを、Trino のプラグインディレクトリにコピーすることでインストールが完了します。
いずれも Trino のバージョンごとに trino-spi のバージョンが上がるため再ビルドは頻繁に必要になります。
また、 trino-spi airlift slice jackson-annotations jol-core 等のいくつかのライブラリは Trino 側で用意されるため、 pom.xml で <scope>provided</scope> を指定します。
Basic Connector
今回はデータソースを追加するために Connector を開発するための手順を追っていきましょう。
公式で trino-example-http という学習用のプラグインが用意されていますので、そちらを参考にします。
https://github.com/trinodb/trino/tree/378/plugin/trino-example-http
ざっくりとしたガイドもドキュメントで紹介されています。 基本的には SPI のインタフェースを満たすようにクラスを作成・適切なメソッドを Override していくという手順です。
https://trino.io/docs/current/develop/example-http.html
プラグインがロードされる際に最初に呼ばれるのが Plugin interface を実装したクラスです。
コネクタを作成する際には、このクラスの getConnectorFactories() メソッドでファクトリ実装を返します。
同様に型定義の場合は getTypes() 、組み込み関数は getFunctions() 等のメソッドでファクトリを返します。
// https://github.com/trinodb/trino/blob/378/plugin/trino-example-http/src/main/java/io/trino/plugin/example/ExamplePlugin.java
public class ExamplePlugin implements Plugin
{
@Override
public Iterable<ConnectorFactory> getConnectorFactories()
{
return ImmutableList.of(new ExampleConnectorFactory());
}
}次に ConnectorFactory は以下のように実装を行います。
getName() で返される文字列は Trino の設定ファイルで利用するものと同一です。
そして create(...) では Connector を返します。
ここでは Google Guice を利用して DI を行った上で Connector インタフェースを実装したクラス ExampleConnector を返しています。
// https://github.com/trinodb/trino/blob/378/plugin/trino-example-http/src/main/java/io/trino/plugin/example/ExampleConnectorFactory.java
public class ExampleConnectorFactory implements ConnectorFactory
{
@Override
public String getName()
{
return "example-http";
}
@Override
public Connector create(String catalogName, Map<String, String> requiredConfig, ConnectorContext context)
{
requireNonNull(requiredConfig, "requiredConfig is null");
checkSpiVersion(context, this);
// A plugin is not required to use Guice; it is just very convenient
Bootstrap app = new Bootstrap(
new JsonModule(),
new TypeDeserializerModule(context.getTypeManager()),
new ExampleModule());
Injector injector = app
.doNotInitializeLogging()
.setRequiredConfigurationProperties(requiredConfig)
.initialize();
return injector.getInstance(ExampleConnector.class);
}
}Connector Interface を実装する ExampleConnector の実装は以下のようになっています。
冗長な部分は少し端折って記載しています。
主にスキーマ等の情報を Trino へ伝える ConnectorMetadata 、Split と呼ばれるデータソースのグループ化された行の集まりを取得する ConnectorSplitManager 、実際の行を取得するための ConnectorRecordSetProvider を返しています。
他にもトランザクションを管理するためのメソッド等が用意されています。
// https://github.com/trinodb/trino/blob/378/plugin/trino-example-http/src/main/java/io/trino/plugin/example/ExampleConnector.java
public class ExampleConnector implements Connector
{
@Inject private final LifeCycleManager lifeCycleManager;
@Inject private final ExampleMetadata metadata;
@Inject private final ExampleSplitManager splitManager;
@Inject private final ExampleRecordSetProvider recordSetProvider;
@Override
public ConnectorMetadata getMetadata(ConnectorSession session, ConnectorTransactionHandle transactionHandle)
{
// ConnectorSessionには、接続元の認証情報等が格納されている
return metadata;
}
@Override
public ConnectorSplitManager getSplitManager()
{
return splitManager;
}
@Override
public ConnectorRecordSetProvider getRecordSetProvider()
{
return recordSetProvider;
}
// 省略
}ConnectorMetadata Interface を実装する ExampleMetadata は以下のようになっています。
こちらでは主に、スキーマの一覧・テーブルの一覧・テーブルのカラム定義等を返しています。
シグネチャを見ればだいたい何をやるべきかわかると思うので、実装は省略しました
今回のケースでは利用されていませんが、パフォーマンスチューニングを行うにあたって非常に重要な PushDown を行うのもこのクラスになります。
// https://github.com/trinodb/trino/blob/378/plugin/trino-example-http/src/main/java/io/trino/plugin/example/ExampleMetadata.java
public class ExampleMetadata implements ConnectorMetadata
{
@Inject private final ExampleClient exampleClient;
@Override
public List<String> listSchemaNames(ConnectorSession session) { /* 省略 */ }
@Override
public ExampleTableHandle getTableHandle(ConnectorSession session, SchemaTableName tableName) { /* 省略 */ }
@Override
public ConnectorTableMetadata getTableMetadata(ConnectorSession session, ConnectorTableHandle table) { /* 省略 */ }
@Override
public List<SchemaTableName> listTables(ConnectorSession session, Optional<String> optionalSchemaName) { /* 省略 */ }
@Override
public Map<String, ColumnHandle> getColumnHandles(ConnectorSession session, ConnectorTableHandle tableHandle) { /* 省略 */ }
@Override
public Map<SchemaTableName, List<ColumnMetadata>> listTableColumns(ConnectorSession session, SchemaTablePrefix prefix) { /* 省略 */ }
private ConnectorTableMetadata getTableMetadata(SchemaTableName tableName) { /* 省略 */ }
private List<SchemaTableName> listTables(ConnectorSession session, SchemaTablePrefix prefix) { /* 省略 */ }
@Override
public ColumnMetadata getColumnMetadata(ConnectorSession session, ConnectorTableHandle tableHandle, ColumnHandle columnHandle) { /* 省略 */ }
@Override
public ConnectorTableProperties getTableProperties(ConnectorSession session, ConnectorTableHandle table) { /* 省略 */ }
}class ExampleMetadata の getTableHandle(...) で返される ExampleTableHandle は ConnectorTableHandle Interface を実装していますが、その Interface の定義は空です。
Trino は分散システムで複数のノードにまたがってクエリが実行されます。
その際にテーブルやカラムの情報をノード間で受け渡しを行うことが有るのですが、その際に jackson で JSON にシリアライズした上で送信し、受信したノード上でデシリアライズを行います。
ですので、こちらは ConnectorTableHandle はプラグイン上でテーブルを識別するための情報が含まれていれば良く、フィールドの内容は Trino から参照されることはありません。
同様に ColumnHandle ConnectorTransactionHandle 等の他の Handle についても同様の実装です。
// https://github.com/trinodb/trino/blob/378/plugin/trino-example-http/src/main/java/io/trino/plugin/example/ExampleTableHandle.java
public final class ExampleTableHandle implements ConnectorTableHandle
{
private final String schemaName;
private final String tableName;
@JsonCreator
public ExampleTableHandle(
@JsonProperty("schemaName") String schemaName,
@JsonProperty("tableName") String tableName)
{
this.schemaName = requireNonNull(schemaName, "schemaName is null");
this.tableName = requireNonNull(tableName, "tableName is null");
}
@JsonProperty public String getSchemaName() { return schemaName; }
@JsonProperty public String getTableName() { return tableName; }
public SchemaTableName toSchemaTableName() { return new SchemaTableName(schemaName, tableName); }
// 省略
}ConnectorSplitManager Interface を実装する ExampleSplitManager クラスは以下のようになっています。
こちらでは Trino がデータを取得する 1 つの単位である Split を返します。
Trino はクエリを実行するノードに Split をいくつか割り当ててクエリを開始します。
Trino において Split は並列動作の単位ですので、期待する並列数よりも多い Split を返すことが望ましいです。
代表的にはファイル等の単位で Split を作成する事が多いです
。
掲載している参考実装は複数の URL から取得したファイルに対してクエリを行う物となっていますので、URL ごとに Split が作成されています。
例では全ての Split 情報を収集した上で FixedSplitSource クラスを返していますが、ストリーミングすることも可能ですので大量の Split が作成される場合は収集が完了する前にクエリを開始することが出来ます。
// https://github.com/trinodb/trino/blob/378/plugin/trino-example-http/src/main/java/io/trino/plugin/example/ExampleSplitManager.java
public class ExampleSplitManager implements ConnectorSplitManager {
@Inject private final ExampleClient exampleClient;
@Override
public ConnectorSplitSource getSplits(
ConnectorTransactionHandle transaction, // トランザクション情報
ConnectorSession session, // 接続元情報
ConnectorTableHandle connectorTableHandle, // テーブル情報
SplitSchedulingStrategy splitSchedulingStrategy,
DynamicFilter dynamicFilter)
{
ExampleTableHandle tableHandle = (ExampleTableHandle) connectorTableHandle;
ExampleTable table = exampleClient.getTable(tableHandle.getSchemaName(), tableHandle.getTableName());
// this can happen if table is removed during a query
if (table == null) {
throw new TableNotFoundException(tableHandle.toSchemaTableName());
}
List<ConnectorSplit> splits = new ArrayList<>();
for (URI uri : table.getSources()) {
splits.add(new ExampleSplit(uri.toString()));
}
Collections.shuffle(splits);
return new FixedSplitSource(splits);
}
}ConnectorRecordSetProvider Interface を実装した ExampleRecordSetProvider は以下のようになっています。
対象 Split/カラム等の情報を受け取って実際に行を返す RecordSet オブジェクトを作成するのみの簡単な実装になっています。
// https://github.com/trinodb/trino/blob/378/plugin/trino-example-http/src/main/java/io/trino/plugin/example/ExampleRecordSetProvider.java
public class ExampleRecordSetProvider implements ConnectorRecordSetProvider {
@Override
public RecordSet getRecordSet(ConnectorTransactionHandle transaction, ConnectorSession session, ConnectorSplit split, ConnectorTableHandle table, List<? extends ColumnHandle> columns)
{
ExampleSplit exampleSplit = (ExampleSplit) split;
ImmutableList.Builder<ExampleColumnHandle> handles = ImmutableList.builder();
for (ColumnHandle handle : columns) {
handles.add((ExampleColumnHandle) handle);
}
return new ExampleRecordSet(exampleSplit, handles.build());
}
}RecordSet Interface を実装した ExampleRecordSet は以下のようになっています。
ここでは実際に行の取得を行い、カーソルを生成しています。
// https://github.com/trinodb/trino/blob/378/plugin/trino-example-http/src/main/java/io/trino/plugin/example/ExampleRecordSet.java
public class ExampleRecordSet implements RecordSet {
private final List<ExampleColumnHandle> columnHandles;
private final List<Type> columnTypes;
private final ByteSource byteSource;
public ExampleRecordSet(ExampleSplit split, List<ExampleColumnHandle> columnHandles)
{
requireNonNull(split, "split is null");
this.columnHandles = requireNonNull(columnHandles, "columnHandles is null");
ImmutableList.Builder<Type> types = ImmutableList.builder();
for (ExampleColumnHandle column : columnHandles) {
types.add(column.getColumnType());
}
this.columnTypes = types.build();
try {
byteSource = Resources.asByteSource(URI.create(split.getUri()).toURL());
}
catch (MalformedURLException e) {
throw new RuntimeException(e);
}
}
@Override
public List<Type> getColumnTypes()
{
return columnTypes;
}
@Override
public RecordCursor cursor()
{
return new ExampleRecordCursor(columnHandles, byteSource);
}
}RecordCursor Interface の定義は以下のようになっています。
実際にストレージから取得した値をカラムを指定して取得します。
Trino には整数型として INTEGER SMALLINT INTEGER BIGINT が用意されていますが、全て getLong(...) で取得します。
// https://github.com/trinodb/trino/blob/378/core/trino-spi/src/main/java/io/trino/spi/connector/RecordCursor.java
public interface RecordCursor extends Closeable
{
long getCompletedBytes();
long getReadTimeNanos();
Type getType(int field);
boolean advanceNextPosition();
boolean getBoolean(int field);
long getLong(int field);
double getDouble(int field);
Slice getSlice(int field);
Object getObject(int field);
boolean isNull(int field);
default long getMemoryUsage() { return 0; }
@Override void close();
}しかしながら、型によってはイレギュラーなカーソルの読み出しを行う場合もあるので利用する型の実装をよく確認する必要があります。
例えば TIMESTAMP 型は保持する精度(ミリ秒・ナノ秒等)により、内部的に実装が ShortTimestampType LongTimestampType で切り替わり、それぞれでフィールドの読み出し方が異なります。
また、 MAP 型に対しては getObject(...) メソッドにて Map エントリを返す SingleMapBlock オブジェクトを返す必要があります。
LongTimestampType 実装: https://github.com/trinodb/trino/blob/378/core/trino-spi/src/main/java/io/trino/spi/type/LongTimestampType.java ShortTimestampType 実装: https://github.com/trinodb/trino/blob/378/core/trino-spi/src/main/java/io/trino/spi/type/ShortTimestampType.java
Connector Pushdown
以上、紹介したクラスを組み合わせることで Trino のコネクタを実装することが出来ます。 しかしながら、パフォーマンスチューニングに関しては何も触れていません。 BigQuery 等の DWH はパーティショニング・カラムナストレージ等の技術を組み合わせて、ディスクの読み出し容量を減らした上で、大量のノードでクエリを分散することで高速化を行っています。 これまでに紹介した実装でもクエリの分散は正常に行なえますので、ディスクの読み出しを減らす方法を紹介します。
データベースの分野において、クエリの一部をストレージへ伝えて高速化を行う仕組みを Pushdown と呼びます。 Trino においても Pushdown をサポートしており、前述のディスクの読み出し容量を減らすために利用することが出来ます。 https://trino.io/docs/current/optimizer/pushdown.html
Trino では以下のような Pushdown がサポートされています。
これらは全て ConnectorMetadata Interface で定義されています。
applyProjection特定カラムのみ読み出しapplyFilterWHERE 句で設定されたカラムへのフィルタリングをストレージ側で行うapplyLimitLIMIT 句で設定された数に行の取得を制限applyAggregation集計をストレージ側で行うapplyJoinJOIN をストレージ側で行うapplyTopN他の条件をした際の取得件数を制限applySample行を間引いて読み出し
例えば最も定義が簡単な applyLimit(...) は以下のようになっています。
セッション情報・対象テーブルのハンドラ・件数が引数で渡されます。
ここで Pushdown を行える場合は ConnectorTableHandle に対して LIMIT の数値を設定した上で結果を返します。
ここで設定した数値は SplitManager から取得できますので、適切にストレージ側へ伝えることが出来ます。
// https://github.com/trinodb/trino/blob/378/core/trino-spi/src/main/java/io/trino/spi/connector/ConnectorMetadata.java
public interface ConnectorMetadata
{
default Optional<LimitApplicationResult<ConnectorTableHandle>> applyLimit(ConnectorSession session, ConnectorTableHandle handle, long limit)
{
return Optional.empty();
}
// 省略
}同様の方法で WHERE 等の Pushdown についても実装することでパフォーマンスの大幅な向上が見込めます。 インタフェースの形を見るとわかりますが、読み出し容量の削減以外にもインデックスの利用なども自由に行える形になっています。
Connector Table Statistics
Trino のスケジューラはテーブルの統計情報を利用した上で適切な実行計画を作る仕組みがあります。 https://trino.io/docs/current/optimizer/statistics.html
- テーブル
- 行数
- 各カラム
- 読み取る必要があるデータサイズ
- null の割合
- 値の種類の数
- 最小値・最大値
こちらは Pushdown の値が設定されたあとに取得が呼び出されるので、可能であればその時点で設定された条件に従って統計情報を返すと良いでしょう。
なお、現時点でサポートされているコネクタは Hive のみと、非常に限定的なサポートとなっています。
2022-04-29: Trino では PostgreSQL, MySQL, SQL Server, Iceberg, Delta Lake で統計情報の取得がサポートされているようです。ご指摘いただきありがとうございます。
https://twitter.com/ebyhr/status/1519724462878330880
Enjoy development trino plugin
ざっくりと駆け足にはなりましたが、Trino のプラグインを最低限実装するための方法を紹介しました。 ストレージは有るがクエリエンジンが無いという方は是非実装されることをお勧めします。